2005-08-01
Abstract
In this article looks into one of the problems in detecting attacks for new vulnerabilities: code emulation.
Copyright © 2005 Virus Bulletin
If we look at our IT infrastructure from a security perspective it quickly becomes apparent that securing it will not be possible unless a thorough approach is taken. One of the best formal methods is risk analysis as it allows proper allocation of budget and placement of safeguards. However, one thing that is often overlooked (besides the fact that conducting a proper risk assessment is not a trivial thing and that it's hard to get it right the first time) is the need for two kinds of safeguard that should be placed within the business process. While currently we have a lot of safeguards that (try to) protect us from well-known, well-defined threats or vulnerabilities, the list of safeguards that can protect us from future attacks is not very long. One class of tools that tries to tie both ends together is Intrusion Detection and Prevention Systems (IDP/IPS). In this article we will look into only one problem in detecting attacks for new vulnerabilities: code emulation.
To be able to detect not only known attacks at known vulnerabilities, but also new attacks targeting known vulnerabilities and new attacks targeting new vulnerabilities, we need to use a certain approach. Not every approach is applicable here, especially if it is intended for use in a real-life environment, but we can achieve the above partially by using one (or better yet all) of the following methods:
Note that not all of the methods listed above work well at network level or host level. Method 1 seems to be the easiest to implement, especially at network level, assuming we have a packet reassembly component in place. For example, many buffer overflow exploits use so-called 'nop-sled', which in its most trivial form is a stream of no-operation instructions. For example, the IA32 architecture has a single-byte NOP instruction that can be used. In fact, many exploits for IA32 systems use nop-sled based on a set of NOP instructions. Using this observation we can create a simple rule for detecting such exploits. In this case we don't need to know the particular exploit or the vulnerability being targeted by it at the time of creating the rule.
alert ip $EXTERNAL_NET $SHELLCODE_PORTS -> $HOME_NET any (msg:"SHELLCODE x86 NOOP"; content:"|90 90 90 90 90 90 90 90 90 90 90 90 90 90|"; depth:128; reference:arachnids,181; classtype:shellcode-detect; sid:648; rev:7;)
Figure 1. Snort rule (from shellcod.rules file) detecting the simplest nop-sled for IA32.
Today's customers are not interested in detecting attacks - they simply want to keep the bad guys off their systems. To do this we need some kind of prevention measures. In our last case this seems to be simple. If we detect nop-sled, we can break the connection before it reaches the target. However, to deploy any mechanism in a real-life business environment we need a very low number of false positives and false negatives, otherwise it could impact the business more than the attacks themselves.
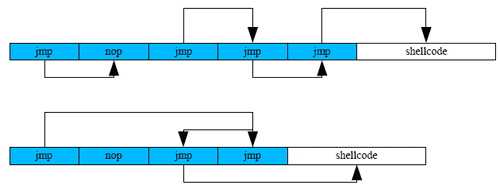
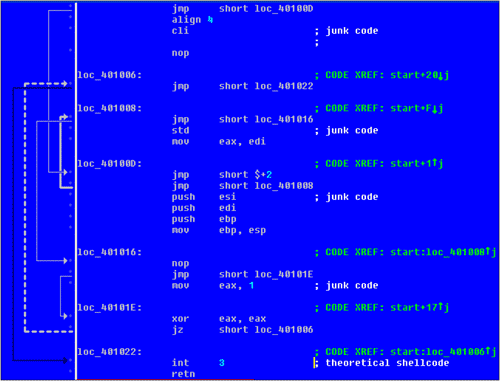
If you run snort or any other NIDS/IPS with a similar rule to that shown in Figure 2 you will quickly find out that the number of false positives can be high. Also, even if we need to use only single-byte instructions in nop-sled there are a lot more instructions we can use besides just NOP. Within the IA32 architecture we can use: cli, sti, cld, std, push, pop, popad, pushad etc. If we can control the target or predict how the EIP register will behave during overflow we can also use other instructions that occupy more than one byte in memory. Taking this idea further we can even use conditional and unconditional jump instructions. Figure 2 illustrates such a construction, while Figure 3 shows an IA32 example implementation.
When analysing Figure 3, take a look at the loc_40101E location. To be able to predict whether the jump will occur we need not only to analyse the code flow but also to keep the CPU state including registers and flags.
We also need to remember about the need to emulate unconditional jumps and calls. The code in Figure 3 is built in such a way that, between jumps (that would occur on a real CPU) there is junk code which would influence the emulation process. We need to skip the junk code just as the real CPU does. We also need to remember about loop constructs. It may be possible to use an instruction like LOOP or JCXZ / JECXZ, which should also be emulated. Actually many polymorphic decryption loops use the LOOP or Jnn instruction on IA32.
Loops based on the LOOP instruction on IA32 are an interesting case because, at first, it would seem logical that this is how a compiler would generate the following C code:
int i;
for(i = 0;i < 10;i++)
__asm__("nop");However, both GCC and VC compiler use conditional jumps. Here is a disassembly of the above loop compiled with GCC 2.95.3 on OpenBSD 3.1:
0x17a3 <main+11>: movl $0x0,0xfffffffc(%ebp) 0x17aa <main+18>: nop 0x17ab <main+19>: nop 0x17ac <main+20>: cmpl $0x9,0xfffffffc(%ebp) 0x17b0 <main+24>: jle 0x17b4 <main+28> 0x17b2 <main+26>: jmp 0x17bc <main+36> 0x17b4 <main+28>: nop 0x17b5 <main+29>: incl 0xfffffffc(%ebp) 0x17b8 <main+32>: jmp 0x17ac <main+20> 0x17ba <main+34>: nop 0x17bb <main+35>: nop 0x17bc <main+36>: xor %eax,%eax 0x17be <main+38>: jmp 0x17c0 <main+40> 0x17c0 <main+40>: leave 0x17c1 <main+41>: ret
If we remove the nops and function epilog we end up with the following construction:
0x17ac <main+20>: cmpl $0x9,0xfffffffc(%ebp)
0x17b0 <main+24>: jle 0x17b4 <main+28> ;if i <= 9
;goto 0x17b4
0x17b2 <main+26>: jmp 0x17bc <main+36> ;exit from
;loop
0x17b4 <main+28>: nop ;execute loop scope
0x17b5 <main+29>: incl 0xfffffffc(%ebp) ;increment
;loop counter
0x17b8 <main+32>: jmp 0x17ac <main+20> ;jump to the
;beginning of loop
0x17bc <main+36>: xor %eax,%eax ;executed after
;loop endsThis observation allows us to make a rule to look for loop constructions that are not typical for compiler-generated code. This could be done with our emulator. However we still have to keep in mind that some applications besides shellcodes are written in assembly language. It is also important not to take our assumption about shellcode construction too far. For example, the assumption that every shellcode is written directly in assembly language is false. Some of the first publications about buffer overflow exploitation on Win32 platforms were based on writing shellcode in C and doing cut-and-paste operations from a high-level language compiled disassembly. So we can find shellcode which looks just like compiler-generated code.
Now let us assume that we have built a code emulation engine that can read payload from incoming packets and try to execute it in a sandbox to evaluate whether it is legal or dangerous code that should be stopped. As one might expect, there are many problems with such an approach. For now, we will ignore the use of polymorphic shellcode in the wild. First we will try to define the requirements for such an emulator.
To be more than just a signature-based system we need to keep the state of the emulated CPU. This raises an important question: which CPU should we emulate? A better question would be how to distinguish from the packet payload which architecture those opcodes are for. One very crude solution would be to map the destination IP addresses with a particular system platform and CPU architecture. Knowing the operating system of the target could also be useful because it could help the emulation process. For example, we can ignore, to some extent, the system calls in Linux shellcode (int 80h) if the destination IP is a Windows system (system calls are made with the help of the call instruction). Now we see another issue: we need to emulate system calls, or at least be able know what particular functions do to evaluate code. While in Linux/Unix systems this could be easy, it could be a bit trickier for Windows or IOS systems, where calls or jumps are being made to execute system functions.
Imagine for a moment that we have solved all of the above problems. After all, we could do some statistical tests to determine CPU type, or try to disassemble part of the payload to see if we can get something meaningful for the particular architecture. We don't need to emulate all of the called functions - we can look only for those which are typical for shellcodes. At this point we come across another important problem: is it data or code?
This is a very important question. In the case of IA32 there is no easy way of telling whether the particular byte stream is data or code. So if we emulate only the payload from one packet we don't know whether it is real code or just data. This is why some snort shellcode rules are disabled immediately, because of the high number of false positives. Look at Figure 1 again - theoretically, a perfectly legal application can contain such a byte stream in its data section.
One solution would be to reassemble the packet stream, extract all payloads and put it into our emulator. Unfortunately we still don't know where the data and code lie in memory. So the above solution could be applied in the case of sending an executable object of known format like ELF, A.OUT or a PE file. However, it would fail in the case of shellcode.
Another approach would be to analyse traffic at application level. In some cases it would be easier to distinguish data from code. This approach requires the IDS/IPS system to be aware of the particular server application and interact with it. There are very few solutions that can do this currently for more than one application. Usually application firewalls/ IDS/IPSs are designed to work with one particular application like IIS.
We have ignored polymorphic shellcode (Figure 4) until this point. The main idea behind it is to make signature-based detection impossible. To achieve this, real shellcode code is encrypted and encapsulated into a new structure that contains nop-sled built with many different instructions and a decryption loop. After decryption the execution flow is directed at real (decrypted at this time) shellcode. n0P SLE4d Decryption loop Encrypted shellcode Ret address
Even a very simple INC/DEC or XOR encryption loop hides strings like /bin/bash or cmd.exe and system function calls which are typical for shellcode operation. If the new nop-sled is built from many different instructions that can occupy more than one byte and the decryption loop is random, a simple signature-based system will not be able to detect it without a high level of false positives. Some solutions like [ 1 ] use a characteristic-based approach looking for particular bytes. Another approach has been suggested in [ 2 ]. Here the authors propose a method based on analysing the return address of shellcode. If it lies within a particular range we can assume that it is a working exploit. The one problem is that we still need to be able to identify the area of ret address space within the packet's payload.
Emulating even a simple decryption loop takes some CPU resources. Decrypting encrypted shellcode can be easy if there is a decryption key or the key is a byte or word value. But what will happen if the decryption loop uses a brute force attack to decrypt the shellcode because there is no decryption key included? This method has already been used in malware [ 3 ] and there is no reason why attackers couldn't use it at network level. As one might guess this poses a serious problem to a code emulator: it would either fail or use a lot of system resources. It would also take time to evaluate code, which brings us back to the business requirements that must be met to deploy a solution in a real-life environment.
The aim of this article was to scratch the surface of the real problem that IDS/IPS vendors try to battle. Personally, I think they are losing this battle for now. It seems that some attack detection should be done strictly at host level. HIDS should also introduce additional safeguards at the system level to stop particular attack classes. Such architecture should be strengthened with network-based IPSs. It will be interesting to see for how long we will have to deal with buffer overflow vulnerabilities. The introduction of different stack protection techniques in conjunction with safe versions of C/C++ functions ([ 4 ], [ 5)] should make buffer overflow attacks extinct within the next five to eight years. Then the presented emulator will have many more problems to battle.
[1] 'Polymorphic Shellcodes vs. Application IDSs', Next Generation Security Technologies: http://www.ngsec.com/docs/whitepapers/polymorphic_shellcodes_vs_app_IDSs.PDF .
[2] , , , 'Buttercup: Network-based Detection of Polymorphic Buffer Overflow Exploits', Department of Computer Science University of California: http://www.citris.berkeley.edu/events/spotlight/posters/posters_1003/1_felix_wu.ppt
[3] , 'Bad IDEA', Virus Bulletin, April 1998: http://www.peterszor.com/idea.pdf
[4] StrSafe: http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnsecure/html/strsafe.asp
[5] SafeStr: http://www.zork.org/safestr/