2005-08-01
Abstract
For increased intrusion detection efficiency, more and more honeypots must be set up in different locations, especially in different subnets. Usually this requires a large amount of administration effort, involving fine-tuning each of the honeypots' behaviour each time a new infection technique or exploit is discovered. This article describes how one company managed to extend their simple honeypot, designed to capture worms, to an easy manageable honey net.
Copyright © 2005 Virus Bulletin
Over the last few years worms and bots in particular have become a penetrating widespread threat. Anti-virus companies have developed better and better heuristic detection against these pests, but some are still slipping through. Therefore, the old method of adding signatures as soon as a new variant shows up remains very important. At a time when more than 40 new bot variants are appearing each day, it is extremely important to have a binary sample of each for analysis in house.
A traditional honeypot that captures the latest variants is quite an efficient technique. However, a slight disadvantage of the technique is that most of the attacks will be from the same subnet and after a while you will be aware of all the bots around the honeypot, and fewer new variants will be discovered.
For increased efficiency, more and more honeypots must be set up in different locations, especially in different subnets. Usually this requires a large amount of administrative effort, involving the fine-tuning of each of the honeypots' behaviour each time a new infection technique or exploit is discovered.
This article describes how we managed to extend our honeypot, which was specially designed to capture worms, to a honey net that solves this problem using a new technique. All information about new attacks and samples are collected at a single point. Further configuration and changes can be made from a single point and all of this is possible in real time.
One Sunday evening in 2004, I spent some time watching connection attempts on various ports (such as 135, 139 and 445) on my router at home and was amazed by how many were blocked. From previous analysis in our virus lab, I knew that these were attempts to infect my machine with copies of worms like Lovsan, Sasser, Korgo and various other bots.
In order to capture a binary I redirected one of those ports to a VMware Windows XP machine without SP and without patches. After a couple of minutes, I managed to get a binary copy of a bot that seemed to be a brand new variant since it was not detected by our product at that time. The idea of an automated system was born.
Only a couple of months earlier, I had played with the fingerprinting tool called nmap [ 1 ] I saw it as a requirement that our honeypot should behave in the same way as the vulnerable Windows XP machine mentioned above. If an attacker uses this tool or any other fingerprinting technique, he should come to the conclusion that this is a real machine waiting to be infected.
From time to time, I see port scans on several of the well-known ports without any infection attempt to follow. This could be some kind of automated or manual collection of IP addresses for an infection process planned to take place at a later stage. It could also be an attempt to determine whether the machine matches certain conditions.
Be that as it may, the machine should respond in the same way as a regular machine on most ports. I felt that it would be best to create a honeypot that is able to simulate more than just a machine including some standard services. Moreover, it should be possible to simulate a Mydoom backdoor or a vulnerability such as the one Opaserv uses, for instance.
Finally, I decided to use WinpkFilter [ 2 ], a packet-filtering framework that gives you full control of each packet arriving and leaving the machine. According to Lance Spitzner's classification of honeypots [ 3 ], I would categorize this as a low interaction honeypot, specially designed to capture the binaries of worms and nothing more than that.
The first version was able to simulate the MS04-011 vulnerability [ 4 ], which was being used extensively by W32/Korgo at that time, and the famous DCOM RPC vulnerability MS03-026 [ 5 ], which was first used by W32/Lovsan (alias Blaster).
By simulating these two vulnerabilities, I was able to capture 11,190 working binaries within three weeks in August 2004. It was rather interesting that a significant number were infected with the file infector virus W32/Parite. These were various infected worms that merely carried the old file infector along with them. Statistics from the first three weeks after the honeypot went online can be seen in Figure 1.
2777 Worm/Korgo.U 1399 Worm/Korgo.S 605 Worm/Rbot.DO 554 Worm/Korgo.X 543 Worm/Rbot.JL 436 Worm/Rbot.DA 370 Worm/Rbot.GT 310 Worm/SdBot.JG 295 Worm/Korgo.Q 293 Worm/Korgo.P 288 W32/Parite 3320 Other ---------------------- 11190 Total
Figure 1. Honeypot statistics from a three-week period in August 2004.
Overall, 142 different variants of various worms were captured. After a very successful start, with sometimes as many as a dozen new variants a day, fewer and fewer new binaries were discovered. After a while, I started to implement more vulnerability behaviour as well as support for some common commands from the SMB protocol that were used by worms in order to propagate (see Figure 2).
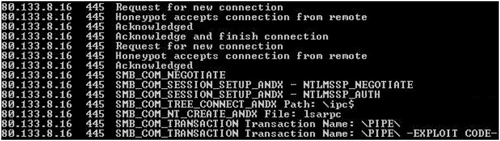
Figure 2. Support was implemented for some common commands from the SMB protocol that were used by worms in order to propagate.
After another peak of new variants, things returned to the previous low level of activity. An analysis of the source IP addresses showed that around 80 per cent of the infections originated from the same subnet. At that time, the honeypot was located in the Deutsche Telekom AG subnet and the IP address was 80.133.x.x.
Deutsche Telekom is the largest ISP in Germany and the connection with the Internet is terminated each day. Therefore, you will get a new IP address each time you dial up. Unfortunately, I found myself always in the 80.133.x.x range, even if I reconnected dozens of times. I was sure that there were other, yet-to-be-seen variants that were active in other subnets.
The reason is that most worms try addresses that are similar to their own, in order to increase their chances of success. Usually this trick is guaranteed to increase the chances of a worm's success both because similar addresses are more frequented than randomly generated ones, and because there is a high chance of address validity [ 6 ].
Eventually, my colleagues from the virus lab helped me out and set up new traps in other subnets. Even those who live just a few kilometres away might be in a different subnet, presupposing that their dialup receiver provided by the ISP is a different one.
The distribution of the traps worked pretty well and we got new variants of worms that we had not seen before. Every time a new trap was put online, we were able to see another peak.
A mailing routine was added to collect all the samples on a central server. The binary was shipped along with the original IP and port, timestamp, original filename and the whole infection log, which could help to determine bugs in the program as well as transmission errors or ideas for further implementation. At the time the email arrived on the server, a couple of error checks were made, a decision was made as to whether it should be forwarded to the lab for further analysis, and statistics were gathered.
The conclusion seems obvious: it is important to have as many traps as possible, keeping in mind that they should be in different subnets.
All this gave rise to other problems as I had to maintain more than one trap, update it, collect and interpret the results. Moreover, I had data only from successful infection processes. Imagine if there is a new technique to compromise a machine or there is the need to implement further commands from the SMB protocol or even listen on other ports.
From the current point of implementation, there were some drawbacks that forced a redesign of the whole concept and that practically made the change from one or more stand-alone honeypots into a distributed honey net.
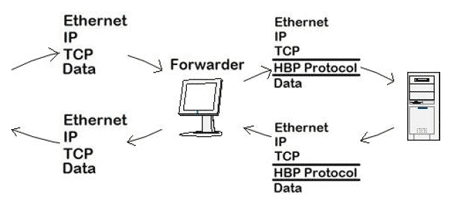
The new recommendation was to design a system with as many traps as possible. Although it should be possible to collect and watch the infection processes at a single point, the solution was to split the honeypot into two parts. The first is called the 'Forwarder' and the other is called the 'MainPot'.
As you might have anticipated, the Forwarder will redirect the traffic to a certain IP address and a certain port that can be configured using a config.cfg file along with the installation process. The traffic arriving on certain ports at the Forwarder side is not just a simple redirect using NAT [ 7 ]. As we wanted to create reliable statistics, to watch out for seeding attempts of new malware and to figure out in which subnets certain malware is active, another layer on top of the TCP protocol was implemented (see Figure 3).
The new protocol (see Figure 4) is 16 bytes long and contains data such as an identifier, original IP, original source and destination port, number from the config.cfg file and some free bytes reserved for further ideas.
The identifier helps the MainPot to distinguish whether the packet really comes from a Forwarder, if it was just a port scan or any other data arriving on that port. The number set in the config.cfg file could be anything from 1 to 65,535 and uses two bytes in the protocol. This number must be set manually during the Forwarder's first installation process.
The purpose of this is so that each Forwarder can be recognized, even if the IP address changes. It makes sense to know which ISP and location you are using, as the ISP might implement port filtering on common malware ports from one day to another and you won't receive anything and might wonder why. Exactly this happened to one of the Forwarders placed in Bucharest, Romania in June 2005.
Other important data is the original source and destination port. It is necessary to ship this data along, as the MainPot must know how to react when constructing the answer packet. The original IP address is shipped in order to provide statistics.
However, the original IP address, original source and destination port are needed later when the Forwarder has to strip down the protocol and construct the final answer packet. In fact, this is the same thing the MainPot does in the first step when a new packet arrives. Using the original ports and addresses the packet is reconstructed as it arrives on the Forwarder side. It is then saved to a log file including IP + TCP + Data - even the Ethernet layer is saved there. The purpose of the saved packets is described in the next section.
The MainPot searches its database for the type of data that the answer packet should contain. If it is successful, which means that this was already implemented, it constructs the answer packet. Finally, the HBPot protocol header is built in again and sent to the Forwarder. This has the simple task of replacing the original IP and the ports, then recalculating the checksums before sending the answer packet to the attacker.
Depending on the connection and location, the delay between the Forwarder and the MainPot is around 200ms. Each of the honeypot parts needs less than 10ms to construct the packet, which means that most of the time is spent 'on the road'.
As mentioned before, every incoming packet including all layers is saved to a file. It is not only the incoming packets but also the outgoing packets that are stored in this file.
The infection log is saved in a folder with the name of the original source IP address combined with the timestamp of the first communication. The time frame during which this is valid is only a couple of minutes - the reason being that (at least in Germany) your IP address is different every time you connect to the Internet. A new connection attempt at some later point will result in the creation of another folder, in order not to append the previous infection log with data that should be kept separately. Of course, this could be a reinfection attempt from the same machine, but it is also possible that it is a different machine that is using this IP address now.
Nevertheless, the infection log is very important when it comes to unsuccessful infections. There could be many reasons for these, such as a broken Internet connection, the machine on which the worm is running having been turned off during the transfer, and so on.
It is rather interesting when a new technique is used in order to infect a machine. This could be a new exploit or just another command from the SMB protocol that has not yet been implemented and it will simply result in the packet not being answered at the MainPot side.
Let's assume that the never-seen-before exploit code 'MSxx-xxx' is used and it is not yet implemented. The infection log would save the communication up until the point at which the MainPot doesn't know how to go further. In order to implement the next step, I have created a tool that is able to read the infection log and simulate the whole communication against the aforementioned vulnerable Windows XP VMware machine in a secure environment.
The whole communication is simulated, starting with the three-way handshake up to the last packet and finally I can figure out what the MainPot should have had answered in order to go further with the communication.
At this point, I am able to implement this answer package into the MainPot and hope for an attacker using the same exploit to go another step further. A binary - probably from another source - would help a lot as I could simply create a full infection trace using Ethereal and implement all necessary communication in a single step. Without a binary to analyse in the virus lab, this is the only way to go further and finally capture the binary by myself.
There are some ideas that the simulation against a vulnerable VMware machine could take place in real time as long as the communication with the Forwarder is pending. At the time of writing, this has not yet been implemented and I cannot say if this is fast enough as the connection is usually dropped within seconds if no answer packet has arrived.
In order to create a successful honeypot it is important to have as many sensors as possible. In fact, it does not really matter if these are Forwarders or stand-alone honeypots, although the forwarder technique makes a lot of things easier and allows real-time changes and analysis for the whole honey net.
[1] 'Polymorphic Shellcodes vs. Application IDSs', Nmap: http://www.insecure.org/nmap/
[2] WinpkFilter: http://www.ntkernel.com/
[4] Microsoft Security Bulletin MS04-011: http://www.microsoft.com/technet/security/bulletin/MS04-011.mspx
[5] Microsoft Security Bulletin MS03-026: http://www.microsoft.com/technet/security/bulletin/MS03-026.mspx
[6] , 'Advanced survival techniques in recent Internet worms', Virus Bulletin International Conference Proceedings, 2004, abstract: http://www.virusbtn.com/conference/vb2004/abstracts/gszappanos.xml