2006-02-01
Abstract
A common criticism of statistical spam filters (such as SpamBayes, DSPAM and POPFile) is that they can be 'poisoned' by inserting random words into spam messages. John Graham-Cumming looks at the evidence and attempts to answer the question: does Bayesian poisoning exist?
Copyright © 2006 Virus Bulletin
A common criticism of statistical spam filters (such as SpamBayes, DSPAM and POPFile) is that they can be 'poisoned' by inserting random words into spam messages.
Postini, for example, makes the claim in one of its white papers [1] that the addition of legitimate-seeming words to spam messages can cause them to slip through spam filters. Worse, Postini claims, it can also cause false positives when users correct the spam filter's error by assigning a spammy probability to a good word.
Cloudmark's chief scientist Ved Prakash made the following claim in a news article [2]: 'The automata will just keep selecting random words from the legit dictionary ... When it reaches a Bayesian filtering system, [the filtering system] looks at these legitimate words and the probability that these words are associated with a spam message is really low. And the program will classify this as legitimate mail.'
Meanwhile, Process Software claims [3] that Bayesian poisoning has little effect: 'Even though the following tricks to poison Bayesian databases have little (if any) success, they still appear very frequently in spam messages.'
In December 2002, Paul Graham (who is arguably the father of Bayesian spam filtering) addressed the question of poisoning [4]. He said: 'To outweigh incriminating words, the spammers would need to dilute their emails with especially innocent words, i.e. those that are not merely neutral but occur disproportionately often in the user's legitimate email. But these words (the names of one's friends and family, terms one uses in one's work) are different for each recipient, and the spammers have no way of figuring out what they are.'
Confused? The opinions appear to depend on the nature of the product of those expressing them: Postini and Cloudmark sell non-Bayesian systems and claim that poisoning works; Process Software's system and Paul Graham's system are both Bayesian and claim the opposite.
In this article I will review the published data on poisoning Bayesian spam filters to answer the question: does Bayesian poisoning exist? I will then show a novel way of poisoning a Bayesian spam filter and measure its effectiveness.
At the Spam Conference held at MIT in 2004 I presented two possible attacks on POPFile's Bayesian engine [5]. One was unsuccessful and the other worked, but was impractical. In doing this I identified two types of poisoning attack: passive (where words are added without any feedback to the spammer) and active (where the spammer gets feedback after the spam has been received).
The passive method of adding random words to a small spam was ineffective as a method of attack: only 0.04% of the modified spam messages were delivered. The active attack involved adding random words to a small spam and using a web bug to determine whether the spam was received. If it was, another Bayesian system was trained using the same poison words. After sending 10,000 spams to a single user I determined a small set of words that could be used to get a spam through.
Of course, the simple countermeasure of disabling remote images (web bugs) in emails eliminates this problem.
At the CEAS conference in 2004, Wittel and Wu presented a paper [6] in which they showed that the passive addition of random words to spam was ineffective against CRM-114, but effective against SpamBayes with 100 words added per spam.
They also showed that a smarter passive attack, adding common English words, was still ineffective against CRM-114, but was even more effective against SpamBayes. They needed to add only 50 words to a spam to get it past SpamBayes.
However, Wittel and Wu's testing has been criticized due to the minimal header information that was present in the emails they were using; most Bayesian spam filters make extensive use of header information and other message metadata in determining the likelihood that a message is spam. A discussion of the SpamBayes results and some counter evidence can be found in the SpamBayes mailing list archive: http://mail.python.org/pipermail/spambayes-dev/2004-September/thread.html#3065.
All of these attacks are what I refer to as type I attacks: attacks that attempt to get spam delivered. A type II attack attempts to cause false positives by turning previously innocent words into spammy words in the Bayesian database.
Also in 2004 Stern, Mason and Shepherd wrote a technical report at Dalhousie University [7], in which they detailed a passive type II attack. They added common English words to spam messages used for training and testing a spam filter.
In two tests they showed that these common words decreased the spam filter's precision (the percentage of messages classified as spam that really are spam) from 84% to 67% and from 94% to 84%. Examining their data shows that the poisoned filter was biased towards believing messages were more likely to be spam than ham, thus increasing the false positive rate.
They proposed two countermeasures: ignoring common words when performing classification, and smoothing probabilities based on the trustworthiness of a word. A word has a trustworthy probability if an attacker is unlikely to be able to guess whether it is part of an individual's vocabulary. Thus common words are untrustworthy and their probability would be smoothed to 0.5 (making them neutral).
At the 2005 CEAS conference Lowd and Meek presented a paper [8] in which they demonstrated that passive attacks adding random or common words to spam were ineffective against a naïve Bayesian filter. (In fact, they showed, as I demonstrated back in 2004, that adding random words improves the spam filtering accuracy.)
They demonstrated that adding 'hammy' words - words that are more likely to appear in ham than spam - was effective against a naïve Bayesian filter, and enabled spam to slip through. They went on to detail two active attacks (attacks that require feedback to the spammer) that were very effective against the spam filters. Of course, preventing any feedback to spammers (such as non-delivery reports, SMTP level errors or web bugs) defeats an active attack trivially.
They also showed that retraining the filter was effective at preventing all the attack types, even when the retraining data had been poisoned.
The published research shows that adding random words to spam messages is ineffective as a form of attack, but that active attacks are very effective and that adding carefully chosen words can work in some cases. To defend against these attacks it is vital that no feedback is received by spammers and that statistical filters are retrained regularly.
The research also shows that continuing to investigate attacks on statistical filters is worthwhile. Working attacks have been demonstrated and countermeasures are required to ensure that statistical filters remain accurate.
All of the attacks described above either add innocent words to a spam message to get it past a Bayesian filter, or add words that will increase the filter's false positive rate when the user reports a delivered spam.
Another way to get spam messages past the filter is to reduce the probability of any spammy word. If it were possible to fill the Bayesian database with many unique spammy words, then the probability of any individual spammy word would be reduced, and when words are combined to score an individual message the spam score would be forced lower. The spammers' aim would be that the spam probability drops enough to cause spam messages to appear to be ham and consequently be delivered.
Bayesian spam filters typically calculate the spam probability for a word as either the number of messages in which the word appears divided by the total number of spam messages in the training set, or as the total number of times the word appears divided by the total number of words in the training set. By adding more unique spam words, each in individual messages, the spam probability for every spam word can be lowered in either case.
To test this theory I took a standard naïve Bayesian spam filter implementation written in C and trained it using spams and hams from the SpamAssassin public corpus (see http://spamassassin.apache.org/publiccorpus/). The filter was configured to run in train-on-everything mode (i.e. once the filter had determined the classification of a message it retrained itself automatically on the message, believing its own classification).
A separate corpus of 10,075 email messages drawn from my own mail (6,658 ham and 3,417 spam) was used to test the filter. Running through the messages in a consistent, yet random, order yielded a ham strike rate (also referred to as the false positive rate: the percentage of ham messages incorrectly identified) of 0.06% and spam hit rate (the percentage of spam messages correctly identified) of 99.80%.
To test the theory that delivering spam messages containing a single word could bias the filter's spam probabilities so that more spam would slip through, I randomly inserted spam messages containing a single randomly generated eight-letter word. The header was from a real spam message in the corpus (which caused the message always to be identified as spam and then trained on) and the body consisted of the eight-letter word.
The eight letters were chosen randomly from the alphabet to create a large number of unique words (a sample word might be HLAHEJGE). As the one-word spams were delivered, the unique eight-letter words would be added to the database (by the train-on-everything mode), thus lowering the probability for every spam word in the database.
I ran 11 tests: the first test had no one-word spam messages added and acted as a baseline for the effectiveness of the filter; the second test added 10 randomly generated one-word spam messages per spam message in the corpus (i.e. with 3,417 spams in the corpus, 34,170 one-word spams were inserted); the third test added 20 random one-word spams and so on up to 100 one-word spams per real spam message (for a total of 341,700 one-word spams). The existing spam and ham messages were run through the filter in the same order each time and the effectiveness of the filter measured without counting the additional one-word spams.
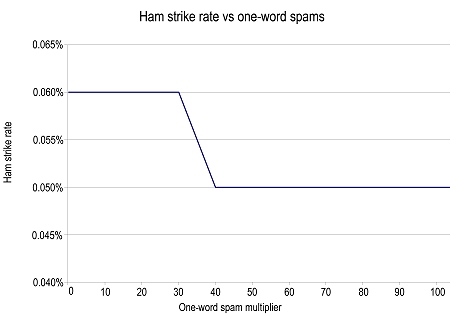
Figure 1 shows the effect of these one-word spams on the ham strike rate. With 40 one-word spams per real spam (for a total of 136,680 one word spams) the ham strike rate improves, indicating that the message that was previously incorrectly identified as spam has shifted (correctly) to be a ham. That's the first indication that the spam probabilities are lowering, causing the filter to bias towards messages being classified as ham.
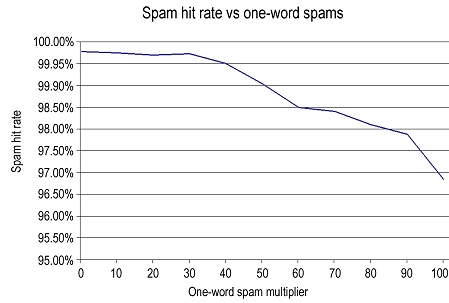
Figure 2 shows the effect of the same one-word spam messages on the spam hit rate. The filter's accuracy at spotting spam deteriorates as the number of one-word spams is increased. With 347,100 one-word spams added the filter has dropped from 99.80% accurate at spotting spam to under 97%.
However, to put these figures into perspective, this attack required 341,700 additional spams to get 101 out of 3,417 spam messages delivered and at the same time the attack improved the filter's ability to identify ham messages correctly.
Although the attack is impractical, and easily defeated by purging rarely seen words from the database or by not using the train-on-everything methodology, it does work. And for spam filters that calculate the probability of a word based on the total word count (and not the total message count), the attack could be made more effective by including many random words in each message, thus requiring fewer messages to be delivered before having an effect.
The evidence suggests that Bayesian poisoning is real, but either impractical or defeatable. At the same time the number of published attack methods indicates that Bayesian poisoning should not be dismissed and that further research is needed to ensure that successful attacks and countermeasures are discovered before spammers discover the same ways around statistical spam filtering.
[1] Postini white paper, 'The shifting tactics of spammers'. See http://www.spamwash.com/whitepapers/WP10-01-0406_Postini_Connections.pdf.
[2] 'Constant struggle: how spammers keep ahead of technology', Messaging Pipeline, 2005. See http://www.messagingpipeline.com/news/57702892.
[3] Process Software white paper, 'Common spammer tricks'. See http://www.process.com/techsupport/spamtricks.html.
[4] Graham, Paul; 'Will filters kill spam?'. See http://www.paulgraham.com/wfks.htm.
[5] Graham-Cumming, John; 'How to beat an adaptive spam filter', MIT Spam Conference 2004. See http://www.jgc.org/SpamConference011604.pps.
[6] Wittel, Greg and Wu, S. Felix; 'On attacking statistical spam filters’, CEAS 2004. See http://www.ceas.cc/papers-2004/slides/170.pdf.
[7] Stern, Henry; Mason, Justin and Shepherd, Michael; 'A linguistics-based attack on personalised statistical email classifiers'. See http://www.cs.dal.ca/research/techreports/2004/CS-2004-06.shtml.
[8] Lowd, Daniel and Meek, Christopher; 'Good word attacks on statistical spam filters', CEAS 2005. See http://www.ceas.cc/papers-2005/125.pdf.