2006-03-01
Abstract
Andrej Bratko describes a spam filtering technique that treats email as a sequence of characters, rather than a collection of words.
Copyright © 2006 Virus Bulletin
We know from experience that emails advertising prescription drugs are typically spam, so an email containing the word 'viagra' is usually destined straight for the junk folder. But there are reportedly 1,300,925,111,156,286,160,896 ways to spell 'viagra', all of which are legible to the human eye [1]. How can we train an automatic filter to cope with this diversity of natural language?
Although a spam filter might anticipate all plausible and implausible character substitutions and spelling variations, spammers have a reputation for inventing new, creative ways of getting their message across. To complicate matters further, formatted text provides infinite possibilities for additional obfuscation.
Surely, there must be a more elegant solution.
In the following article we explore a filtering approach that is less sensitive to such obfuscation tactics, by treating email as a sequence of characters, rather than a collection of words.
Most content-based spam filters convert the textual contents of an email into a set of attributes that describe the message in machine readable form. This is commonly referred to as the 'bag-of-words' representation, reflecting the fact that attributes generally correspond to word-like tokens extracted from the text. Statistical filters use this representation in combination with some machine learning algorithm.
At best, these algorithms can learn to discriminate spam from legitimate email in the token world. Their success depends crucially on the assumption that the token world adequately approximates the actual information conveyed in the messages, as interpreted by a human. However, this is not always the case, especially in the adversarial spam filtering setting.
An obvious caveat here is that there is no a priori definition of similarity between tokens. The words 'viagra', 'vi@gra' and 'v1agra' are simply considered different and the filter is unable to generalize whatever it has learned about one to the other.
It is this weakness that is commonly exploited by spammers with various obfuscation tactics, such as common character substitutions and formatting tricks. Although the success of such tactics is hard to measure in practice, a good indication of their effect is their widespread use in the wild. It is clear that spammers would not obfuscate messages if these tactics were fruitless.
Many spam filters take measures to detect obfuscation, or even try to deobfuscate messages. We explore a different route here by omitting the tokenization step altogether and using data compression algorithms that operate directly on character sequences.
Probability plays a central role in data compression. The general idea is to assign shorter codes to more probable characters and longer codes to less probable ones. In fact, if we know the exact probability distribution over all possible messages emitted by some information source, we can compress these messages optimally. Here, messages are independent sequences of characters, which can be arbitrarily long. Given some training data, statistical data compression algorithms learn a probability distribution over such sequences.
Compression algorithms learn, for example, that the text 'The weather is pleasant today' is much more probable than 'Vreme je danes prijetno' in English text. However, had we trained the algorithm on a Slovenian text corpus, the latter sequence would undoubtedly receive a greater probability.
It is straightforward to see how these algorithms can be used to determine the language of an unknown piece of text, or, along the same lines, to determine whether a piece of text is in fact a piece of spam. We simply train two compression models, one from examples of spam, and another from examples of ham (legitimate email). The classification outcome is determined by the model that finds the target text more likely.
Formally, Bayes rule is used for classification by approximating the conditional document probability given the class, with the probability assigned to the document by the respective compression model. The theoretical relationship between data compression and Bayesian classification is elaborated further in our technical report, which is available online [2].
So how exactly do data compression methods estimate the probability of every possible sequence of characters? They certainly cannot be estimated directly, since there are an infinite number of such sequences.
To make the inference problem tractable, sources are usually modelled as Markov sources with limited memory. This means that the probability of each character in a sequence depends only on its context – a limited number of characters immediately preceding it. The probability of a sequence of n characters sn1 = s1 . . . sn is then
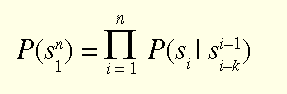
The number of context characters, k, that are used for prediction is usually referred to as the order of the compression model. The parameters of such models are next-character probabilities, and a different set must be learned for each possible combination of preceding characters.
Higher order models are more realistic – however such models also require a lot of training data to obtain accurate parameter estimates, since the number of parameters grows exponentially with the order of the model. For example, an order-k model requires 256k ·255 parameters, if we assume that each character has 256 possible values.
Compression algorithms generally try to make the most of the limited training data available by blending the predictions of different order models. The idea is to use higher-order models only when the amount of data is sufficient to support them.
The next section contains a fairly condensed technical description of the PPM compression model, and can be skipped on first reading.
The Prediction by Partial Matching (PPM) compression algorithm is among the best-performing compression schemes for lossless text compression.
An order-k PPM model works as follows: when predicting the next character in a sequence, the longest context found in the training text is used, up to length k. If the target character has appeared in this context in the training text, its relative frequency within the context is used as an estimate of the character's probability.
These probabilities are discounted to reserve some probability mass, which is called the escape probability. The escape probability is effectively distributed among characters not seen in the current context, according to a lower-order model.
The procedure is applied recursively until all characters receive a non-zero probability, ultimately terminating in a default model of order –1, which always predicts a uniform distribution among all possible characters.
Many versions of the PPM algorithm exist, differing mainly in the way the escape probability is estimated. In our implementation, we used what is known as escape method D, which simply discounts the frequency of each observed character by 1/2 occurrence and uses the gained probability mass as the escape probability.
A spam filter based on the PPM-D compression algorithm was submitted for evaluation in the spam filtering track of the 2005 Text REtrieval Conference (TREC). The goal of the spam track is to provide a standard evaluation of current and proposed spam filtering approaches. (For an overview of the TREC 2005 spam track, including a description of the evaluation tools and measures, see VB, January 2006, p.S2.) The four corpora used for the evaluation contained a total of 318,482 messages, 113,129 of which were spam.
An online learning scheme that mimics real email usage was adopted for the evaluation: messages are presented to the filter in chronological order. For each message, the spam filter must first make a guess as to how likely it is that the message is spam, after which it is communicated the gold standard judgment representing the true classification of the message as spam or ham. This allows the filter to update its statistics before assessing the next message.
The performance of spam filters is usually measured in spam misclassification and false positive rates. There is typically a trade off between these two measures, so that one of them can be improved at the expense of the other by adjusting a fixed filtering threshold. The higher the threshold, the less likely we are to falsely identify a legitimate message as spam, but more spam will also make it past the filter.
The primary measure used for evaluating spam filters in TREC was the area above the Receiver Operating Characteristic curve (ROCA). This measure equals the probability that a legitimate message appears more 'spammy' to the filter than a spam message (a certain error), which is estimated over all pairs of legitimate and spam messages in the dataset. The measure captures the filter's behaviour across all possible filtering thresholds.
Table 1 lists summary performance measures on the aggregate results over all four corpora used for TREC. Only the seven best-performing systems from different organizations are shown here – a comprehensive list of all results can be found in the TREC proceedings [3].
| Filter | ROCA % | SMR % at 0.1% FP | SMR % at 0.01% FP |
|---|---|---|---|
| ijsSPAM2 | 0.051 | 3.78 | 19.81 |
| crmSPAM2 | 0.115 | 3.46 | 29.30 |
| lbSPAM2 | 0.132 | 6.75 | 25.84 |
| tamSPAM1 | 0.172 | 9.10 | 77.77 |
| yorSPAM2 | 0.316 | 21.14 | 45.69 |
| kidSPAM1 | 0.768 | 66.13 | 96.34 |
| 621SPAM1 | 1.008 | 4.36 | 40.67 |
Table 1: Comparison of filters in the area above the ROC curve statistic (ROCA) and spam misclassification rates (SMR) at 0.1% and 0.01% false positives. A smaller number indicates a better performance.
The table lists the filters in order of decreasing performance according to the area above the ROC curve statistic. The list includes open source filters, such as CRM114 (crmSPAM2), DBACL (lbSPAM2) and Spam-Bayes (tamSPAM1), as well as IBM's SpamGuru (621SPAM1). The system developed at the Jozef Stefan Institute (labelled ijsSPAM2) is based on an order-6 PPM-D compression model.
The primary motivation for using data compression as a spam filtering tool is that the approach conveniently circumvents the need for tokenization. Patterns of punctuation and other special characters which are hard to model as a 'bag-of-words' are naturally included in the model.
Figure 1 shows some examples of the types of patterns picked up by the PPM model – each character is coloured according to how 'spammy' it looks to the filter, with red indicating spam and green indicating ham. Typical character substitutions used by spammers are recognized easily, as are URL obfuscation tactics. Useful patterns can also be found in the non-textual message headers.

Figure 1. How does PPM see messages? Each character is coloured according to how ‘spammy’ it looks to the filter: red indicates spam, green indicates ham (good email).
Some interesting patterns that are typical of legitimate email are also shown, such as message headers that are only included in replies and line prefix characters that usually accompany forwarded text.
Character-based compression models are a promising technique to help future statistical spam filters combat the ever-increasing volumes of spam as well as newer, more malicious forms of unsolicited email. The mere fact that these algorithms operate in the world of character sequences makes it more difficult to find ways of defeating them. Surely, any form of obfuscation only makes it easier for the filter to recognize that the message is spam.
Although no publicly available spam filters currently use data compression algorithms, any off-the-shelf implementation of PPM, such as Charles Bloom's PPMZ [4], can easily be adapted for this task.
[1] 'How many different ways are there to spell Viagra?'; http://cockeyed.com/lessons/viagra/viagra.html.
[2] Bratko, A. and Filipic, B.; 'Spam filtering using compression models'; http://ai.ijs.si/andrej/papers/ijs_dp9227.html.
[3] Proceedings of the 14th Text REtrieval Conference (TREC 2005); http://trec.nist.gov/pubs.html.
[4] Charles Bloom's PPMZ; http://www.cbloom.com/src/ppmz.html.