2007-04-01
Abstract
What lies ahead for anti-virus testing programmes with the introduction of new protection schemes that move away from scanner-based detection? Richard Ford and Attila Ondi look to the future of AV testing.
Copyright © 2007 Virus Bulletin
Product reviewing has a long and sometimes contentious history in the anti-virus world. Furthermore, unlike word processors or video games, a user of an anti-malware product is ill-placed to measure the utility of the particular protection scheme, for although its usability and performance can readily be determined, the crucial question of how much protection a product provides is elusive.
As if this were not enough, new developments in anti-malware research mean that this problem could worsen considerably, leaving not only users but reviewers confounded when attempting to evaluate new product developments. As forewarned is forearmed, this article outlines some of the history of anti-virus product reviews and certification, and highlights some of the challenges new technology could bring with it.
The goals of the product tester vary dramatically depending on the audience of the tests. Despite these variations, testing an array of products usually involves either putting them through some sort of ‘pass/fail’ tests (like product certification schemes), or ranking them in an ordinal way – usually by deciding which is best when measured against a particular set of criteria.
To date, tests of anti-virus software have evolved greatly from their fairly simple beginnings. Whereas initially products were ranked based only on raw detection scores, added emphasis was soon placed on the detection of viruses ‘in the wild’ (though the concept of ‘in the wild’ has become increasingly dated with time, and it is no longer entirely representative of the threats facing users), response time, and the overhead the product imposed on the host operating system.
Clearly, how one balances the importance of different areas is somewhat subjective – for example, is missing one zoo virus 100 times less important than missing one wild virus? Most people are fairly comfortable reading these kinds of tests, simply because they are so common.
However, one of the important things to realize is that current tests are easy because the information provided by the products has always essentially been binary: products generally detect an object or they don’t. Thus, it has been easy to count false negative and false positive rates, and provide readers with good, useful data.
The binary nature of traditional anti-virus products - detect or not - meant that there really wasn’t much meaning in any middle ground. Files detected using heuristics or other ‘softer’ techniques generally count toward detection, so reviewers have not had to deal with degrees of detection in any great way.
In addition, tests can usually be performed using just one or two machines; complex networks are seldom required. The benefit of the anti-virus software is measurable at the individual machine level: the better-protected a single machine is, the better for all. Thus, our review criteria are geared toward classifiers that are single-unit centric.
It would be wonderful if reviewers could continue these reviewing practices for the foreseeable future, but the truth is that as new threats evolve, new protection paradigms also emerge.
For example, in the anti-spam world, several different products have investigated the use of throttling techniques to limit the number of spam messages a user receives. Such a product never actually determines whether or not an individual message is spam. Instead, as mail from a particular endpoint exceeds some threshold or other metric, a delay is injected into the processing of subsequent messages.
This technique can be extremely effective, but its local impact is hard to measure without some understanding of the global picture. If a customer implements the system, what levels of spam reduction might (s)he expect? Testing the system against a corpus of spam/non-spam messages is meaningless; only by understanding the dynamics of the whole system can one determine the expected outcome.
Similarly, a product that works by the throttling of network traffic for worm limiting is difficult to evaluate: from the perspective of a single computer, protection is not provided. Holistically, however, the speed (and therefore, ultimately, the magnitude) of outbreaks can be shifted radically. This is in step with biologically inspired systems, for example, which are relatively accepting of sacrificing single units or cells for the good of the whole.
Other new technologies in the anti-virus world are equally challenging for reviewers, as they break away from single machine solutions. Essentially, anything that doesn’t operate at the level of a classifier (‘run this, don’t run that’) is well outside the reach of current reviewing methodologies.
While it would be nice to ignore these issues, doing so tends to exacerbate the anti-virus industry’s legendary resistance to new ways of doing things. New ideas that emerge need to be compared meaningfully to current best practice.
However, if we need to examine the system as a whole, testing becomes a whole lot more difficult as it’s not practical to do this for real. Instead, we need some way of creating our own reality for the purpose of experimentation. That means either an analytical model, a testbed, or a simulation; unfortunately, there’s no obvious right answer, as each solution has its own problems.
Simplistically, a testbed seems like the most attractive approach, as it’s really quite close to what reviewers do already. A test environment is created and the products are tested under ‘real world’ conditions. Unfortunately, for products that act more systemically, that’s a tall order. Many thousands of nodes might be required to really understand how the product would fare under typical scenarios. Furthermore, generating realistic conditions (for example, realistic simulation of a user browsing the web) is non-trivial.
Analytical models are attractive in that they are elegant and provide a clean way of calculating how a product might fare. Unfortunately, anything but the simplest scenarios lead rapidly to intractable mathematics. Furthermore, most systems incorporate a large amount of randomness. Consider an email worm, for example, which hits a large mailing list by chance early on in its spread. Such a worm would likely be more widespread than one which initially was ‘unlucky’ in spread.
Getting such data from analytical models is difficult, but an important question for those interested in a product’s effectiveness. It’s much more useful, for example, to know that 90% of the time the solution works fine, but in 10% of the cases all machines get infected, than it is to know that 30% of machines get infected on average.
The last approach is simulation. Up front, we should disclose that we have a certain amount of bias: Florida Tech has spent a lot of time developing Monte-Carlo-based simulators of virus/worm spread. However, this choice of platform was based upon a careful assessment of the needs for the solution. Simulation provides a relatively cost-effective way of determining the likely range of results from a prevention technique, and can be reconfigured rapidly to explore the effect of different parameters.
Regardless of what technique is chosen, products that affect the population dynamics of spread must be evaluated in terms of those dynamics. Here, a new issue emerges: there is no real agreement on how to compare different spread dynamics.
Virus researchers will be very familiar with the ‘S’ curve shown in Figure 1 illustrating the spread of a ‘typical’ worm over time. Essentially, these curves differ in terms of speed of spread and overall magnitude. However, real-world viruses and worms don’t necessarily follow these curves at all. Different spread methods and preventatives all affect the shape of the spread. How can one compare the spread shapes meaningfully? Figure 2, for example, shows two different worm outbreaks plotted as a function of time. Which shape is more desirable from the perspective of a defender? Are they both bad or is one indicative that a particular product is better than another?
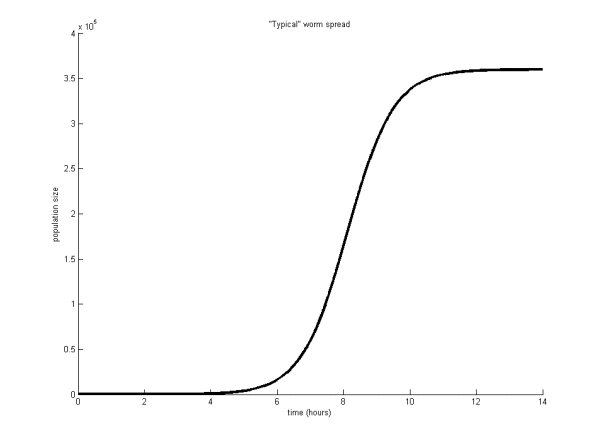
Figure 1. The ‘S’ curve often seen by virus researchers illustrating the spread of a ‘typical’ worm.
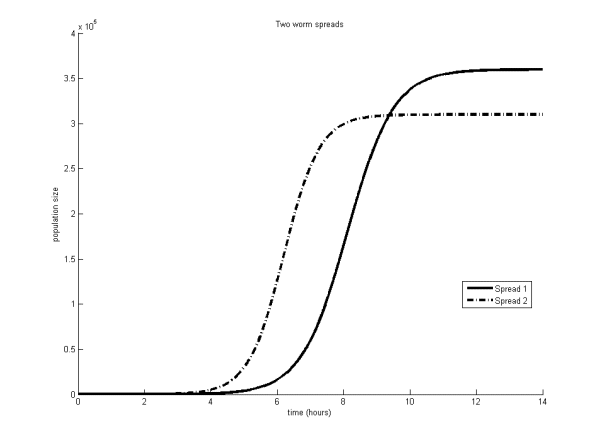
Figure 2. Two different worm outbreaks plotted as a function of time. Which curve is more desirable?
Part of the challenge is that no protection scheme can be evaluated in vacuo. That is, a protection scheme which slows down a virus/worm outbreak is only meaningful if the slowdown is sufficient to allow other protection schemes to be deployed. For example, slowing the global spread of a worm by one minute will have relatively little impact, but slowing it by three days is more significant if users are able to react in this timeframe. If the delay is sufficient, other defences can be put in place; below a certain amount of time, some slowdown makes no real difference to the size of the outbreak.
Part of the challenge for reviewers in the future will be quantifying ‘how much is good enough’. Furthermore, in order for the reviewer to avoid the pitfalls of subjectivity, there will have to be some globally accepted models of reaction times and modification times. How does the public change its behaviour in the face of a particularly nasty worm? These and other difficult questions will have to be explored in order really to compare products which are not simple virus detection engines.
New protection schemes will cause fairly significant problems for those involved in product reviews and certification. In particular, products that move away from binary ‘good/bad’ classification, and which benefit the system macroscopically instead of microscopically, are well beyond the current experience both of reviewers and certification bodies.
This is not ideal for anyone; at best, it leaves users with no information regarding product effectiveness. At worst, it discourages early adopters and could blunt the penetration of innovations which really do benefit the community as a whole. That’s bad for everyone, because at the end of the day the security of the Internet is literally becoming a matter of life and death.
As researchers, as users, and as developers, we need to start thinking about how and why we test products, and how we can prepare for the next wave of innovation. Not doing so is simply shortsighted.