2008-05-01
Abstract
Sorin Mustaca describes the creation of an automated URL filtering system for protecting against phishing websites.
Copyright © 2008 Virus Bulletin
Phishing, spam and malware have become major problems for users of the Internet and for online businesses. Whether delivered as email attachments or via URLs contained in emails, the AV industry is doing its best to protect customers against these threats by gathering and analysing emails with dangerous attachments and by blocking malicious URLs.
Any user who buys a complete security product can expect to receive both local and online protection. Online protection is provided by those products or modules that deal with information coming from outside the system or network on which they are operating. Usually these are the firewall, anti-spam, anti-phishing, URL-filtering and parental control modules. Great importance is currently placed on URL filters, which must be able to prevent the user from accessing phishing and malware-serving sites.
It might seem a trivial task to identify malicious URLs, pack them in a file and send them via updates to the customer so that the URL filter can block them, but the reality is a little more complex.
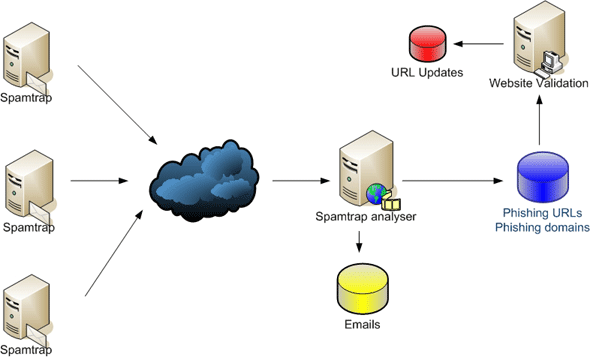
It all starts with spam traps, in which hundreds of thousands of spam, phishing and malware emails are gathered each day. An automated system gathers the emails and splits them into spamming and phishing categories (Figure 1). The emails categorised as phishing are sent to a URL analysis system. This system must check for false positives (i.e. check that the URLs contained in these emails really are malicious), check that the website to which each link points is live and online, and that the website is a phishing site rather than an automatic redirect (this is not as easy as it might seem). The system must also inform several online entities about each malicious URL and prepare a product update for the customers.
This paper will explain how such an automated system was created and how its results are used.
As mentioned, emails are collected in spam traps – mail boxes that have been set up for the sole purpose of collecting spam and which no-one uses for genuine incoming or outgoing email. By using these spam traps we can be certain that the email collected is spam – there is no real person behind the inbox to say ‘I did opt to receive an email from company X, but not from company Y’. Removing the human factor gives us the most secure way of being able to say that a message is unsolicited.
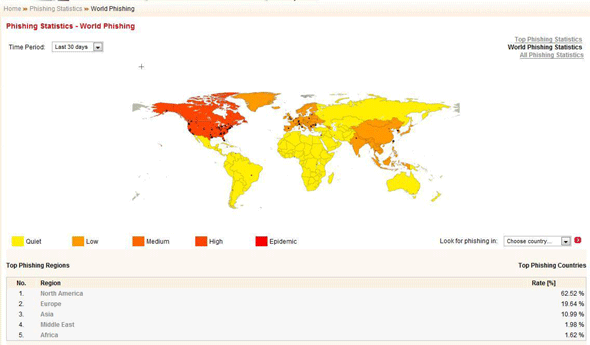
We gather emails from spam traps hosted by mail servers all over the world, giving us an almost global overview of the spam activity in any 24 hours around the planet (see Figure 2). Interestingly, even though we receive emails from many areas around the world, and we sometimes see outbreaks in German, Italian, Spanish, Romanian and others, the vast majority of phishing emails are in English.
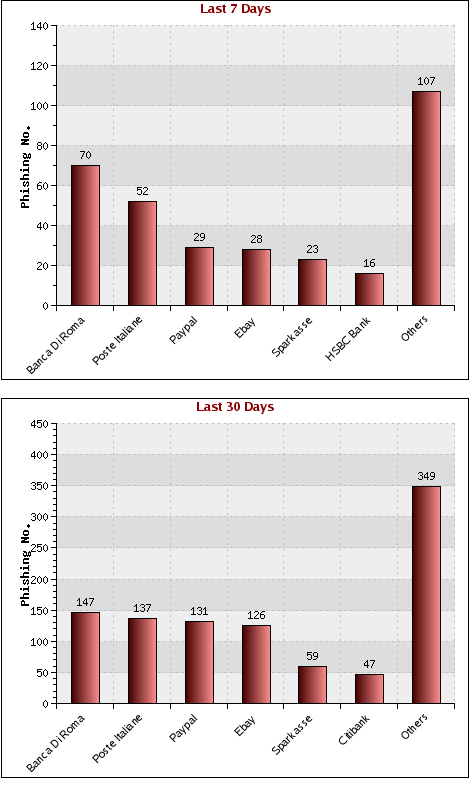
With a finite number of domains seen in the phishing emails, we can also produce statistics about which brands have been targeted and for how long (see Figure 3).
Our anti-spam product can differentiate between the targeted phishing domains and extract the URLs from the emails, so we store this information for further analysis if the content of the website to which the URL points matches the content extracted from the email. This is just another measure to check for false positives and website availability.
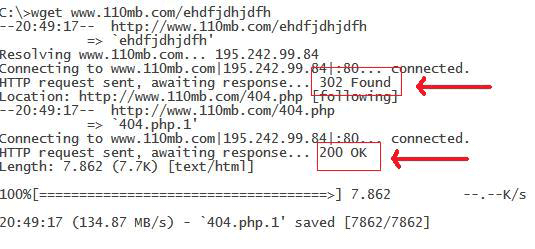
When we first started to develop this anti-phishing system, we created a simple Perl script that launched an external program to test the URLs. If the return value of the program was 0, the website was live; if it was 1, the website was not valid.
However, we soon realized that even though many of the websites were no longer online, the ISPs hosting them were not always returning a simple ‘404 - Page not found’ error, but instead a page containing some form of explanation such as:
‘website not found any more, contact the webmaster’ (the page was simply deleted)
‘website is available for renting’
‘website is no longer valid because it contained a dangerous page’ (contravening the EULA results in automatic deletion)
Alternatively, the URL would be redirected to another website (often the home page of the ISP).
Filtering these special cases would have been a lot easier had all the ISPs used English. The messages were in various languages depending on the ISP’s country of origin, which meant that not all of them could be parsed.
A good idea for handling these pages would be to train a Bayesian filter with the words commonly found in such pages in order to be able to classify them automatically in the future. The filter could be trained with the HTML pages without interpreting them. This would mean that we would have to train with plain HTML and JavaScript code, teaching the classifier to ‘learn’ the techniques this way. This classifier would suffer from the same problems as suffered by all Bayesian filters: trained only with one type of input it will tend to detect more of that input than anything else. This project is currently being investigated.
Fortunately, after analysing some of the substituted web pages, we figured out that there are several common keywords, many of which are international. We are able to filter about 60% of these pages using the keywords.
Even though it is a rather uncommon practice to track each user who clicks on a link, we have seen phishing attacks which were probably intended to be a form of spear phishing (targeted phishing attacks). Each time we notice a URL that has a rather long and randomized parameter at the end, we cut it and we block the entire path up to that parameter. This way, we make sure that all possible combinations of the URL will be blocked.
For example, a long URL like this:
http://s.om.e...d.o.m.a.i.n.net/path/anfang.asp?id=007845698351867681038316409831031 7647934542311555373450305078216
is truncated to this:
http://s.om.e...d.o.m.a.i.n.net/path/anfang.asp
and the entire path is blocked to make sure that access is denied to any possible URL combination.
The system described does not have any AV scanning capabilities, so there are routines in place that filter from the outset any URL whose target is obviously a binary file, which usually proves to be a piece of malware (dropper, trojan, etc.).
Most of the phishing websites we see are ‘classic’ phishing sites (i.e. they imitate the site of a well-known brand and try to steal credentials), but occasionally they also attempt to download a piece of malware in the background. The websites that attempt to do this are in a ‘grey’ area that crosses over between malware and phishing. I have seen only two methods used for downloading the malware: via client-side code (JavaScript) or server-interpreted code like PHP or ASP. A link to such a website looks suspicious from the start:
http://www.google.com/pagead/iclk?sa=l&ai=trailhead& num=69803&adurl= http://some-phishing-website/download.php
There are many possible variations where a background action starts the download:
http://www.google.com/pagead/iclk?sa=l&ai=trailhead& num=69803&adurl=http://www.some-phishing-website.com
Since the analysis system deals only with phishing and not with malware, the only thing that can be done here is to follow the final target and if the content received is binary, discard it, thus protecting the user from a potentially dangerous download.
Result: HTTP/1.1 200 OK Connection: close Date: Sun, 03 Feb 2008 22:48:29 GMT Accept-Ranges: bytes ETag: “86820f-a200-47a510d4” Server: Apache/1.3.37 (Unix) mod_ssl/2.8.28 OpenSSL/0.9.7a PHP/4.4.7 mod_perl/1.29 FrontPage/5.0.2.2510 Content-Length: 41472 Content-Type: application/octet-stream Last-Modified: Sun, 03 Feb 2008 00:54:44 GMT Client-Date: Sun, 03 Feb 2008 22:43:07 GMT
The use of the Google PageAds as seen in the above example is another technique used by phishers. In general, using a search engine to redirect to a website must be seen as a suspicious action:
http://google.com/url?sa=p&pref=ig&pval=2&q= http://www.phishing-site.com http://rds.yahoo.com/_ylt= http://www.phishing-site.com http://aolsearch.aol.com/aol/redir?clickeditemurn= http://www.phishing-website.com
(Note: the above URLs are simplified. Additional parameters have been removed for the sake of simplicity.)
More and more phishing websites are making use of botnets to redirect browsers from one URL to another without the user noticing.
This technique can be achieved using the HTTP Refresh or JavaScript code:
<script language=javascript> top.location=”http://www.phishing-website.com” </script>
The same effect can be obtained with window.location.
Another technique is to use plain HTTP code to refresh the website to another location after an interval:
<head> <meta http-equiv=”refresh” content=”0; url=http://www.phishing-website.com“ /> </head>
The situation becomes interesting when there is a redirect chain through the botnet. The maximum length of redirect chain we detected was four hosts.
There is a danger that these websites will form a loop, either on purpose or by mistake. In this case the parsing module of the system would enter into an endless loop and would have to be interrupted manually. To avoid this we added a maximum recursion limit of 25 redirects.
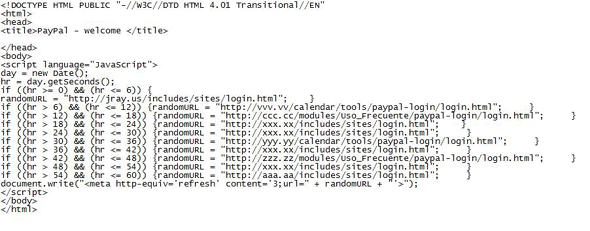
Another technique seen in the wild is to use a rotating refresh. This uses the same technique as the simple HTML refresh, but mixed with JavaScript code in order to self-generate the HTML document. Such a technique of making the website really dynamic could be called ‘polymorphic phishing’ if we borrowed the terminology from malware.
Figure 6 shows some rotating refresh code. Simple analysis of this code shows that every five seconds a new page containing a refresh URL is being generated. The page is refreshed after three seconds, which is way too often.
All the intermediary websites used to reach the final phishing website are saved in our database, regardless of the method used. This way we make sure that nothing gets changed in the redirect chain, up to the final website.
In June 2006 we saw an entire phishing website written in Flash. A 250 Kb Flash file called login.swf was referred to by a simple website like this:
<object classid=”clsid:D27CDB6E-AE6D-11cf-96B8-444553540000” codebase=”http://download.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=4,0,2,0” id=”login” height=”1280” width=”979”> <param name=”movie” value=”login.swf”> <param name=”bgcolor” value=”#FFFFFF”> <param name=”quality” value=”high”> <param name=”allowscriptaccess” value=”samedomain”> <embed type=”application/x-shockwave-flash” pluginspage=”http://www.macromedia.com/go/getflashplayer” name=”login” src=”login_files/login.swf” bgcolor=”#FFFFFF” quality=”high” swliveconnect=”true” allowscriptaccess=”samedomain” height=”1280” width=”979”> </object>

The only way to detect such a website is by parsing the object and analysing the original URL. Of course, this technique is very error prone.
The last and by far the most commonly used technique is to use HTML frames as the entry point in the phishing website. As many as possible are used and in as complicated a way (nested) as possible. But frames can be parsed relatively easily, and this is why we seldom see techniques just using plain frames. They are used together with all the above techniques in order to make parsing as complicated as possible. Also, it seems that the phishers have taken into consideration browsers which do not support frames. Some websites we’ve seen have used JavaScript code to handle this kind of browser.
The solution against this technique is to act as a browser and dive into the frame structure. Of course, this makes everything a lot more complicated because it is not trivial to implement an HTML and JavaScript interpreter in Perl.
All of the above techniques and various combinations of them have been seen in real phishing websites. Creating a validation mechanism for these URLs is not an easy task. When a URL is found, the system has to check if the target website is a real phishing site, an automatic response because the website has been taken down or a false positive. This proves that the fraudsters are no longer script kiddies but knowledgeable developers keen to make a lot of money.
The URL analysis system described in this article is currently maintained semi-manually. The phishing URLs are gathered by a fully automated system, but the analysis of the hyperlinks cannot be fully automated. As in the case of malware analysis, human input is a vital factor, whether that is performing a manual check to see if the system’s decision is correct or upgrading the automatic detection logic. Of course, in the long term, only the latter option is viable, since the unique URLs arrive in their hundreds per month.
The purpose of this system is to determine if the phishing URLs are valid, so that the invalid ones can be discarded before they reach the end users’ filtering mechanisms. This way we can minimize the size of the product updates. Unfortunately, in recent weeks the number of phishing URLs has increased to such a level that it is no longer possible to check every URL at the entry point if we are to deliver the updates in a timely manner. Currently, only basic tests are performed, mostly to prevent the blocking of the ISPs that substitute the ‘404’ error with other pages.