2009-02-01
Abstract
This month sees the introduction of a new testing format to VB’s bi-monthly VB100 comparative review – RAP testing (Reactive And Proactive) will provide deeper insight into products' ability to keep up with the flood of new malware as well as their proactive detection capabilities. John Hawes has all the details.
Copyright © 2009 Virus Bulletin
This month sees the introduction of a new testing format to VB’s bi-monthly VB100 comparative review – one of the biggest changes to the format of the reviews since the inception of the VB100 certification scheme over ten years ago.
The introduction of the new test is the first in a series of planned expansions and improvements to the review data provided by Virus Bulletin – part of a major push to keep our readers better informed of the capabilities of the ever-expanding range of security software on the market.
The development of the new scheme over the past few months has been a lengthy process, with several trial runs and much consultation. A preliminary set of proposals and trial results were first discussed with VB’s board of advisors and other trusted experts last summer, and a second trial round – the methodology adjusted based on initial feedback and with participating products anonymized – was presented to the industry at the VB conference in Ottawa last October. Having taken on board further advice and suggestions and further honed the setup, this month sees the test’s debut in a comparative review (see page 17).
The new test, which we have called ‘RAP’ (‘Reactive and Proactive’) testing, has a fairly simple design.
Once the product submission deadline for a comparative review has been set, we compile a collection of malware samples first seen in each of the three weeks prior to the deadline date. These are referred to as ‘week -3’, ‘week -2’ and ‘week -1’. These test sets form the reactive part of the test, measuring how well product developers and labs have been able to keep up with the steady, and steadily growing, flood of new malware emerging every day across the world. Most of the samples included in these sets are from the daily collections shared between labs and other trusted organizations. They are generally considered to be of high priority, and thus most well-connected malware labs should have access to the samples at the same time as we see them, if not earlier. Establishing whether they can cope with processing and, if needed, adding detection for them is the main aim of this part of the test.
Prioritization is also a major issue here, and some labs may – quite rightly – see it as more important to ensure full detection of particularly prevalent or dangerous items, rather than obscure targeted trojans that are unlikely to reappear. To help cover this angle, we plan to do some prioritization of our own, aligning our sample selection processes with the prevalence data we gather from a range of sources – the aim being to include the most significant items. This is by no means a simple task – prevalence data comes in a variety of forms, many of which are proving increasingly difficult to match to specific items as family and variant group names become increasingly vague and generic. Incoming data with more detail, including specific file identifiers, would be of great help here, and we continue to seek more and better prevalence data to add to our incoming feeds.
Our second trial test included some comparisons between the detection rates achieved when scanning the full incoming feed and those achieved when scanning just those items adjudged to be particularly prevalent. Some very interesting results were obtained. However, part of the reason for filtering incoming samples by prevalence is to reduce the incoming feed to a manageable level which can be checked and validated in the short time available, it would therefore not be appropriate to include such additional data in a full comparative review.
The second prong to this new test is the proactive angle. In addition to the three test sets compiled prior to the product submission deadline, a fourth set of samples is put together in the week following product submission (‘week +1’). This set ought to consist mostly of samples that have not been seen by labs at the time of product submission, and thus will not be specifically catered for by targeted detection signatures. The purpose of this test set is to gauge products’ ability to detect new and unknown samples proactively, using heuristic and generic techniques. Comparing the ‘week +1’ results to the results of the previous three weeks will provide insight into the extent to which vendors rely on proactive preparedness as opposed to rapid response.
This is quite a significant step for VB’s comparative testing, which has in the past set strict test set deadlines – for both malicious and clean items – a few days in advance of the product submission deadline, giving all participants time to ensure their products fully cover the samples in our sets. It also means that full testing cannot begin until a week after the product submission deadline. In the past, the products being tested have been taken in around a month prior to publication of the review, with testing and result processing proceeding throughout the month. As this is already a rather tight schedule – particularly with the growing number of products taking part in recent years – it may be necessary to set the deadlines slightly earlier, but we will endeavour to keep this schedule adjustment to a minimum, to ensure our results are as up to date as possible when published.
The adjustment in the timeline of the test will also put considerable pressure on our malware validation process, which we endeavour to keep as strict as possible given the tight deadlines. We are hard at work attempting to automate the validation process as far as possible to get as many samples processed and included in the test sets as we can.
Astute readers will doubtless have an idea of the likely output of this new test regime. Our prediction from the outset has been that most products will show a slight decline in performance over the three reactive weeks, with detection strongest over the collection of samples seen longest ago (‘week -3’), and a sharper downward step in detection for the proactive week (‘week +1’). This pattern is expected to be especially pronounced for those products whose labs concentrate on fast reaction times over heuristics. In the trials this pattern was followed fairly well at a general level, but at an individual product level there were numerous surprises and anomalies, one particularly interesting trend being a poor showing by many products on the ‘week -3’ set compared to the ‘week -1’ set.
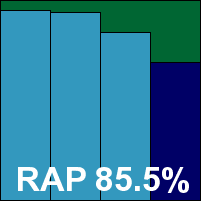

The test results will be represented graphically, as shown above. The three pale blue bars represent (from the left) weeks -3, -2 and -1, while the dark blue bar represents week +1. An overall ‘RAP score’ is also presented on the graph, which represents the average detection over the four weeks. In cases where products have generated false positives in our tests the background of the graph will be coloured red and a large cross, together with ‘FP=’ will act as a warning to the user, showing the number of false positives generated.
Such a wide variety of factors affect the test – from sample selection and classification to national holidays – that such oddities are bound to occur, but any true anomalies should be evened out over the course of time, with repeated tests leaving behind genuine quirks. One of the most interesting aspects of this test will be the picture that builds up over time, as strings of results are put together to show long-term trends and patterns for specific products.
As work on automating various aspects of our lab processes continues, in between busy comparative months we hope to continue to build test sets and measure performance. However, it is likely that this data – generally based on untrusted, unvalidated samples – may only be made available to labs themselves, and probably in partially anonymized format. The extra data gathered in this way may provide even more fine-grained insight when viewed over the long term, and we hope to present periodic analysis of such data in these pages once enough has accumulated.
In order to build up this timeline of results, we must of course start somewhere. So, this month we publish the first set of figures. From the initial idea of RAP testing to this first release there have been numerous tweaks to the format, but the only real test of its viability is its implementation in the setting of a real, busy VB100 comparative review, using genuine, often complex and intractable products. Doubtless this first full outing will highlight a range of issues not previously anticipated, and the format will need a few more tweaks and adjustments. As with the VB100 results themselves, readers should refrain from putting too much faith in a single set of RAP results, but be patient and wait for true patterns to emerge over time.
The results of the RAP tests will form part of the additional data provided in our comparative reviews, alongside other extras such as the detection results of our zoo test sets, our speed and on-access overhead measurements, and my (somewhat subjective) overviews of design and usability.
As such, the introduction of the RAP test does not affect the basic tenets of the VB100 certification programme: the requirement for products to detect the full WildList, both on access and on demand, without false positives. These central certification standards remain unchanged, although we expect to revamp the fine print of the certification procedures in the near future.
In particular, we feel that the definition of ‘on access’ has become somewhat over-specific, with more and more protection software including a wealth of behavioural and HIPS technologies which require full execution of malicious code before they step in. Whether such mechanisms, with their wide sliding scales of detection, warning and blocking, can be included neatly in the VB100 rules without compromising the black-and-white nature of the programme, is something that requires a little more thought and investigation.
As for fully testing the complete range of offerings in the latest generation of desktop suites, including online black- and whitelisting resources, integrated firewalls, web and mail filters and much more besides, it seems likely that this will require a radically new and entirely different approach – something we are working hard on developing. We will, however, continue to run the VB100 certification scheme (with appropriate modifications where necessary) for as long as our readers find it informative and useful.
VB welcomes readers’ feedback on the proposed test methodology. Please direct all comments and enquiries to [email protected].