2009-07-01
Abstract
Typosquatting takes advantage of the typographical mistakes often made by users when entering a website address into a web browser. Amit Verma discusses a two-step approach to combatting the problem, prioritizing the registration of domain typos and detecting typos entered into Internet browsers and email clients.
Copyright © 2009 Virus Bulletin
Typosquatting is a practice that takes advantage of the typographical mistakes (typos) often made by users when entering a website address into a web browser. For example, ‘virustbn.com’ is a typo of ‘virusbtn.com’ in which the letters ‘b’ and ‘t’ are interchanged [very easily done! - Ed].
The low cost of domain registration makes it inexpensive for malicious users to register multiple domains that are very similar to those of popular brands, but which incorporate the sort of typographical error that might be made by a user when entering the URL. These domains are then used to host advertisements and pornographic material, to distribute malware, or are set up for phishing.
A similar practice of email typosquatting has also emerged, which involves registering common misspellings of domain names and setting up mail servers on them to listen for client connections. If a user happens to misspell the domain name while typing an email address, the mail is sent unintentionally to a nefarious recipient. This can lead to data loss from organizations.
Typosquatting can also prove harmful for important events such as the US presidential elections wherein candidates raise funds for election campaigns through their websites. Candidates’ websites often have domain names of considerable character length. If a contributor mistypes the website address – which is not unlikely considering its length and given that the domain name may not have been encountered previously – he might be taken to a site controlled by a typosquatter from which his personal and financial details may be stolen. Furthermore, an increasing number of children are spending time on the Internet, and they are particularly susceptible to this kind of attack.
There is a need for effective techniques to combat this Internet-borne threat. Auto-completion in browsers and email clients mitigates the risk to some extent (recognizing the initial characters typed by the user and automatically filling in the rest, thus reducing the risk of the user mistyping the URL), but it is ineffective for URLs which have not previously been encountered by the browser. The effectiveness of URL reputation-based techniques is also limited given the highly dynamic nature of the content posted on typosquatted domains.
In this article, a two-step approach is discussed which prioritizes the registration of domain typos and effectively detects typos entered into Internet browsers and email clients. The rest of the article is organized as follows: the next section discusses a probabilistic typographical analysis technique that determines the relative frequency of occurrence of typos based on users’ typing error patterns. This is followed by a discussion of a proposed metric named Probabilistic String Similarity Index (PSSI), which is a modified form of the above approach to efficiently detect typos at browsers, email clients and the like. The article closes with a description of the specific areas in which such techniques could usefully be applied.
The first step towards preventing typosquatting should be taken by the entity registering a new domain. Ideally, in addition to registering the new domain, it should register as many typos and look-alikes of the original domain as possible so that even if users mistype the domain name, they will be redirected to the intended website. However, a typical five- to seven-character domain name has nearly 400 potential typos – and even large organizations would struggle to register all of those as domains. As the number of characters in the domain name increases, the number of possible typos grows exponentially. Also, some typo domains may, intentionally or unintentionally, already have been registered by others.
What is needed is a way to identify the typos that have a higher likelihood of occurring compared to others so that the registering of ‘unwanted’ domain names can be prioritized. This can be done using a schema to rank typos based on their frequency of occurrence.
The following are the kinds of typographical error that are usually exploited by typosquatters:
Skip letter: a character is skipped. For example: www.vrusbtn.com.
Double letter: a character is typed twice. For example: www.virussbtn.com.
Reverse letter: two successive characters are interchanged. For example: www.virustbn.com.
Missed key: a character is mistyped with an adjacent key on the keyboard. For example: www.viruabtn.com – here ‘a’ is typed instead of ‘s’.
Inserted key: an extra character is inserted while typing. For example: www.virusdbtn.com.
Missing dot: sometimes the dot is omitted as in http://wwwvirusbtn.com.
Any combination of the above: multiple typographical errors can occur, although the odds of this are quite a lot lower.
We propose a technique of ranking typos based on the probabilistic analysis of typed data. An estimate of the probability of each of the typographical errors mentioned above can be determined by an algorithmic analysis of data gathered from typing test tools. Alternatively, data can be collected from Internet users by the use of Human-Based Computation (HBC) games. These probabilities can be used further to calculate the rank of a domain typo as given below.
The following probabilities are collected from an analysis of typed data:
Pr(Skip letter) - Ps(a), ….Ps (z), Ps (a | x)….Ps (f | s)
where Ps(a) is the probability of skipping character ‘a’ and Ps(a|x) is the probability of skipping ‘a’ given that ‘x’ was the previous character.
Pr(Double letter) - Pd(a), ….Pd (z), Pd (a | x)….Pd (f | s)
where Pd(a) is the probability of entering ‘a’ twice and Ps(a|x) is the probability of entering ‘a’ twice given that ‘x’ was the previous character.
Pr(Reverse letter) - Pr(a | x), ….Pr (x | a)…..
where Pr(a|x) is the probability of interchanging ‘a’ with ‘x’, etc.
Pr(Missed) - Pm(w | s), Pm (d | s), Pm (a | s), Pm (x | s), ...
where Pm(w|s) is the probability of missing ‘w’ given that ‘s’ was the previous character.
Pr(Skip | Missed) is the probability of a ‘Skip’ error given that a ‘Missed’ error has occurred.
For example, let us consider the domain name ‘virusbtn’. Using the probabilities above, the rank of the typo ‘vrustbn’, in which character ‘i’ is missed, and ‘b’ and ‘t’ are interchanged, is calculated as:
Rank(vrustbn) = Pr(Skip) * Ps(i) * Pr(Missed | Skip) * Pm(b | t) * C
where C is a normalization factor.
Figure 1 shows a block diagram for a method that generates and ranks the typos for a given domain name using the probabilistic ranking technique.
An approximate probabilistic model was formulated with this approach to rank typos. Figure 2 and Figure 3 show the results for the domain www.virusbtn.com.
Figure 2 shows the top 20 typo domains (out of 762) for www.virusbtn.com. The domain numbered 13 in Figure 2 existed at the time of conducting this experiment. Figure 3 shows the overall probability values of the top typo domains. Note that these results do not take into account additional information such as the top-level domain – for example,‘c0m’ (character ‘o’ replaced with zero) will not be a possible typo. The demarcation between the overall probabilities of typos can be made finer by using a more accurate probabilistic model.
Using the model, institutions whose sites may be prone to typosquatting can obtain a prioritized list of frequently occurring unwanted domains. They can then register those domains or try to buy them from others. Alternatively, typo domains which cannot be registered (for any reason) can be monitored using visual similarity methods for content that matches that of the legitimate website (which may be a sign of a phishing site). For optimized monitoring, the relative probabilities of the typos can be used to determine the frequency with which the typo domains should be monitored.
Another step towards preventing typosquatting is to monitor the URLs typed by users into their browsers and email clients.
The goal here is to be able to effectively detect common typos at the browser, web proxy or Internet gateway. To accomplish this, a user-specific whitelist can be constructed using email client and browser histories, favourite links, safe site lists and the like. This can be supplemented with lists of popular banking/trading/commerce websites that can be provided by security vendors. A possible approach could be to generate typos for each entry in this whitelist and add the top ranked typo domains for each to the restricted site list of a browser. If a user makes a typographical mistake in typing any domain in the whitelist, he can be given an appropriate warning message. Given the relative ranks of various typo domains, various policies can be introduced. For example, all typos up to rank 10 can be blocked; warnings can be given for typos up to rank 50; and typos ranked greater than 50 can be allowed since they are less likely to be typosquatted domains. Another policy could be to block all typos up to rank 20 (strict monitoring) if the user has a frequent record of visiting the corresponding URL(s).
The probabilistic approach to find relative probabilities can also be modified to cater to typo detection at the users’ end. To eliminate the need for storing possible typos, a string similarity metric is proposed which takes into account both the string Hamming distance and the probabilities of typographical errors. This metric eliminates the need to keep a list of typos of popular URLs at the browser and thus typo detection can be carried out more efficiently. The following is the equation of such a metric called Probabilistic String Similarity Index (PSSI):
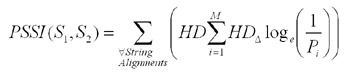
Where:
PSSI(S1, S2) is the probabilistic distance between two strings S1, S2
HD is the Hamming distance of a particular string alignment
M is the number of misplaced character groups
HDΔ is the Hamming distance of the ith misplaced character group
Pi is the probability of an error corresponding to the ith misplaced character group
For example:
PSSI(virusbtn, vrusbtn) = 1*1*log(1/0.5) = 0.301
PSSI(virusbtn, virusbtm) = 1*1*log(1/0.8) = 0.097
The greater the absolute value of PSSI(S1, S2), the greater the distance between the two strings S1 and S2, and the lesser the chance that S1 is mistyped as S2 by a user. The whitelist described earlier can be used to calculate the PSSI value on the fly between the user-typed URL and the ones in the whitelist. The user can be warned if he types a URL with a PSSI value above a certain threshold.
We have discussed how probabilistic typo analysis techniques can be applied in the security domain – to prioritize the registering of unwanted domain names and to efficiently detect typographical errors entered into web browsers.
Along similar lines, email client plug-ins can be developed which can help prevent email typosquatting. This methodology can also be leveraged for parental control, wherein typos of popular children’s websites can be generated on the fly, with the most likely typos added automatically to the restricted sites list of a browser.
Since anti-spam and anti-phishing techniques also involve the detection of typos of popular brands in the contained links, this technique could also play an important role in enhancing anti-spam and anti-phishing engines.