2009-08-01
Abstract
Robert Sandilands describes a clustering technique aimed at helping in the daily efforts of analysing large numbers of samples.
Copyright © 2009 Virus Bulletin
Why do we want to cluster samples?
We receive tens of thousands of executable samples every day, each of which a customer or another party suspects is malicious. This gives us a significant amount of data, but virtually no information.
What is the difference between data and information? In this case, data is a collection of one million files, each with a hash; information is the same collection of files, but clustered into families with known behaviours for each family including characteristics by which the family can be detected.
The first step in turning the massive amounts of data we receive into useful information is to classify the malware. Trying to classify millions of pieces of malware is either computationally extremely expensive or involves an impossible amount of manual labour. We need to be able to separate samples into large groups of samples that have a good probability of being similar. We can then select a smaller subset of each group to analyse, therefore saving time and responding more efficiently to malware. This is what we hope clustering will achieve.
We could decide to add every executable we receive by some hash – there are companies out there that do this. I don’t think we need to go into the folly of that. It would be similar to trying to add detection for a metamorphic file infector using only the hash of the infected file. While we receive millions of samples in a year, I am convinced that this represents fewer than a few thousand different malware families.
The techniques and methods described here are not intended for classification, but there are significant similarities with classification methods and in theory these methods could be used for that purpose. However, I would not recommend it.
The steps that will be followed are:
Feature extraction
Clustering
Validation
This is the process of extracting measurable information from unknown executables. The choice of features is the most important part of the whole process and can determine its success or failure.
Features can be anything that can be measured and that can be used to detect the samples. There is an art to choosing the right features and it might take a few attempts to find the right ones.
For the purposes of this article I will limit feature selection to physical characteristics only. Physical characteristics are those that can be deduced from simple measurements and do not include code analysis or emulation. This has some very obvious limitations but it will also allow a discussion of the process with few reservations and allows the test results to be reproduced easily.
The features used for this article are:
Size of the file
Size of section 1
Entropy of section 1
Size of section 2
Entropy of section 2
Size of section 3
Entropy of section 3
Number of sections
Offset of PE header
Size of appended data
Is it a DLL?
Entry point section number
Each of these measurements will be normalized to within a range of -1.0 to 1.0. If it is not possible to calculate a feature then it will default to zero. If it is a boolean feature then true will become 0.8 and false will become -0.8.
Obviously you could use every possible measurable feature, or even use something like a genetic algorithm to help optimize your choices. In general, you will find that this is an iterative process that will not only have to be repeated several times to get the initial implementation to work, but also will need to be repeated to fine-tune the behaviour of the algorithm over time.
What is clustering? Think of an n-dimensional space where n is the number of features you have. Consider every sample to be a point in that space with the location determined by its features. Clustering is the process of creating n-dimensional spheres in this space that encapsulate groups of samples.
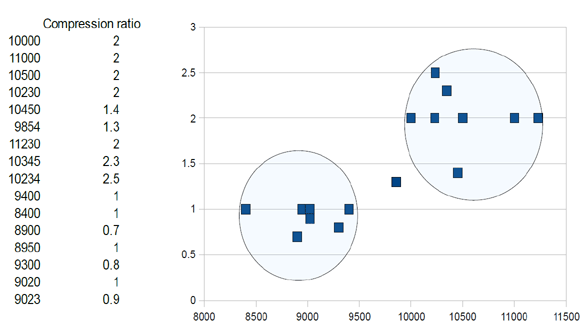
In the simplistic example provided in Figure 1 you can see 16 files listed with their size and compression ratio. This data is completely artificial and was randomly generated to illustrate the technique. In this example it can be seen that there are three clusters of samples. Two of the clusters are highlighted using coloured circles and the third cluster is the single remaining point.
Writing software to perform clustering is a relatively involved process and there are several commercial and open source packages available that implement the more important methods. The one I used for this article is Christopher Borgelt’s implementation [1], which uses a fuzzy logic-based clustering algorithm. What this implies is that every sample has a probability of belonging to every cluster and can belong to multiple clusters with different probabilities.
I also used the excellent pefile Python module [2] to perform feature extraction. Additional scripts were written to generate and normalize the data [3]. This is a mix of Bash, Python and Perl.
This clustering application is based on a fuzzy c-means algorithm.
Boolean logic is a class of logic whereby something belongs to one of two classes. True or false is an example of boolean logic.
In contrast, fuzzy logic and fuzzy membership is a field of logic whereby something has a degree of membership in any number of classes, and that degree can vary between 0 and 100%. It has a membership function that can be used to calculate the degree of membership for each class. For example, ‘hot’, ‘very hot’, ‘mildly hot’, ‘cold’ and ‘very cold’ can be classes in a fuzzy logic system.
If we take a temperature of 30°C then you can say it is most likely hot, a bit very hot and a bit mildly hot. It is not cold or very cold. You can say it belongs to the class ‘hot’ with a degree of 80%, to the class ‘very hot’ with a degree of 10% and to the class ‘mildly hot’ with a degree of 10%. These are obviously only valid if you are talking about the temperature in a room. If you are talking about the temperature in a plant where steel is melted then the numerical values associated with the classes will be significantly different.
This makes fuzzy logic a very powerful tool for describing concepts that are a bit more complex than boolean logic allows for. It also makes it a very confusing field if you only believe in true and false.
The c-means algorithm is one whereby we iteratively minimize the cost of a fuzzy membership function using some method for optimizing the parameters of the algorithm. In this case the parameters are the location and size of the clusters.
The next question is: how do you optimize the parameters?
The method used to optimize the parameters is a variant of the back propagation algorithm also used to train neural networks. It is just a method where the parameters of the function being optimized are adjusted using the gradient of the error function. The error function is chosen to ensure optimal clustering.
The sample set comprised 1,233 samples that varied between 2,346 and 293,760 bytes in size. All the samples were 32-bit Windows PE executables. Some of the samples were packed, others were not.
One of the parameters for the clustering algorithm is the number of clusters it has to use. In this case 15 clusters were selected. The following results were obtained:
Let us assume that any cluster containing more than 50 samples is worth investigating. We assume that considering fewer than 50 samples for a generic signature is inefficient. We can look at the samples that were included in clusters 14, 12, 11, 10, 9, 7, 6, 2, 1 and 0. This allows us to look at a subset of samples from 10 different clusters which represents 1,207 of the group of 1,233 samples provided.
The question is, how useful are these results? It has been stated that the features used in this article are very limited, so it would not be surprising if the results were not very useful.
The samples were selected from our malware archives. A random subset of samples were selected from files that were classified by our scan engine using 10 different names. They were:
W32/Allaple.C
W32/Allaple.J
W32/Backdoor.ALHF
W32/Downloader.ALJ
W32/Downloader.OJ
W32/EmailWorm.AMX
W32/Trojan2.SRR
W32/Trojan.AYPG
W32/Trojan.Inject.A
W32/Worm.MWD
The fact that the clustering algorithm identified 10 clusters, matching the number of malware names used to select the samples, is encouraging.
Table 2 lists the results and the malware names together. The last eight items show a group of samples that were not clustered as would be expected. When investigating these samples they all seemed to be corrupted or not related, indicating a possible issue with the signature used to classify them.
| Samples | Name | Cluster |
|---|---|---|
| 179 | W32/Trojan2.SRR | 0 |
| 160 | W32/Backdoor.ALHF | 12 |
| 157 | W32/Downloader.OJ | 1 |
| 137 | W32/Allaple.C | 9 |
| 112 | W32/Allaple.J | 11 |
| 106 | W32/Trojan.AYPG | 6 |
| 97 | W32/Trojan.Inject.A | 7 |
| 97 | W32/EmailWorm.AMX | 10 |
| 95 | W32/Downloader.ALJ | 2 |
| 66 | W32/Worm.MWD | 14 |
| 11 | W32/Allaple.J | 3 |
| 4 | W32/EmailWorm.AMX | 3 |
| 3 | W32/Allaple.J | 4 |
| 3 | W32/Allaple.C | 13 |
| 2 | W32/Allaple.C | 3 |
| 1 | W32/Worm.MWD | 8 |
| 1 | W32/EmailWorm.AMX | 5 |
| 1 | W32/Allaple.J | 5 |
Table 2. Results and malware names together.
Given the limitations in the features used for this demonstration, this technique showed surprisingly promising results. With more advanced feature selection much better results should be possible.
There is a relatively good match between the samples we already detect using the same name and the results of the clustering. This shows that the technique has some promise when used with a group of unknown samples. The intention of these techniques is to help focus analysis efforts and to simplify the process of selecting samples for generic detection. The quality of the results is dependent on the quality of the feature extraction. A significant amount of time will have to be spent on verifying whether the feature selection is providing good clusters. This verification should be part of the analysis process. A subset of the samples must be analysed to determine their behaviour and the optimal detection. This should also provide feedback for the feature extraction process. As with any non-deterministic method it is not suggested that this method should be used as the only tool to solve a problem, but as part of a larger arsenal of tools.
I hope this article has instilled sufficient curiosity in the subject of clustering to convince readers to investigate it as a viable technology to use to help in the daily efforts of analysing very large numbers of samples.
[1] Borgelt, C. Cluster – Fuzzy and Probabilistic Clustering. http://www.borgelt.net/cluster.html.
[2] Carrera, E. pefile Python module. http://code.google.com/p/pefile/.
[3] Sandilands, R. Other scripts and data. http://robert.rsa3.com/vbcluster09.zip.
[4] Matteucci, M. http://home.dei.polimi.it/matteucc/Clustering/tutorial_html/cmeans.html.