2011-07-01
Abstract
As Python has gained popularity with malware writers, new bytecode obfuscation techniques have started to appear. Aleksander Czarnowski describes some of those techniques.
Copyright © 2011 Virus Bulletin
A lot has changed since I last wrote in Virus Bulletin about reversing Python bytecode (see VB, July 2008, p.10). Many more malicious applications now employ Python, and as a result, new obfuscation techniques have appeared. The game of hiding true source code from third-party eyes has begun. While it is understandable that authors want to protect their intellectual property, the evolution of code obfuscation poses potential problems for vulnerability researchers and malware analysts. The obvious problem is that the same obfuscating techniques that apply to legitimate and harmless software can also be used by malware. This article will share some new experiences and ideas that have come from the evolution of Python bytecode obfuscation. (Source code obfuscation techniques are outside the scope of this article.)
There are a few situations in which there is a legitimate reason for reversing Python bytecode:
Security assessment of the Python module or whole class/package
Vulnerability research/bug hunting
Malware analysis
Incident response/forensic analysis.
Python is very attractive for malware authors due to the fact that, theoretically, the same module can be run on dozens of different platforms without needing to make any changes. Python is also installed on many Linux/Unix systems, and the number of applications that either require or come with an embedded Python interpreter is growing.
To understand the process of reversing Python bytecode modules we first need to understand the bytecode format and how it can be obfuscated.
The first four bytes are used by the Python interpreter to decide if it can execute compiled bytecode. The next four bytes are used to decide whether the compiled file should be used instead of the source file of the same name. For example, when executing a line such as:
python simple_script.py
the Python interpreter will first check whether simple_script.pyc (the compiled file) exists. If it does, then it will check whether the timestamp from the compiled file is more recent than that of the source (.py) file. If it is, the compiled file will be executed instead of interpreting the source file (and in turn compiling it to bytecode). It is worth noting that, should any error occur during file interpretation, the Python interpreter will not create a bytecode file. However, it is possible to generate a bytecode file that will throw an exception during execution. So compiled bytecode cannot be treated as evidence of a lack of code errors.
Python marshalled bytecode can be deserialized. The result of such an operation is a ‘code’ object. One of the most important object properties from our perspective is co_code, which is the string representation of the object’s byte code.
Another file type that is very similar to pyc is pyo. Like pyc files, pyo files are the result of compilation to bytecode, however in this case optimization is turned on (-o option).
Two more file formats are worth mentioning at this point: pyz and egg.
A pyz file is a so-called ‘squeezed’ module, optionally compressed using zlib. SqueezeTool provides the interface to create such files. This format allows many Python modules to be stored in one file. On Unix systems a pyz file can start with a shebang line in order to allow direct execution by invoking the Python interpreter (if installed). Additionally, some tools can add the __zipmain__.py module to the archive.
Egg format files contain a zip archive with package files and resources plus an EGG-INFO subdirectory. This folder contains project metadata.
Finally, there are tools that enable a native executable binary to be created from Python source code. Examples of such applications are py2exe (Windows), cx-freeze (BSD/Linux) and py2app (OS X). The code generated by these tools is beyond the scope of this article.
| File offset | Size | Meaning |
| 0 | 4 | Four-byte magic number – unique for every Python version, with the last two bytes always set to: 0x0D, 0x0A |
| 4 | 4 | Four-byte timestamp which Python uses to decide whether the module should be recompiled from the source (.py) file if the .pyc file has been found |
| 8 | ? | Marshalled code object |
Table 1. Pyc file structure
Pyc files are not Python’s only executable form besides source files. Python extension modules written in C/C++ come in the form of DLLs (on Windows systems) and ELF files (on Linux/BSD systems). These modules contain compiled native code and are platform dependent, so unlike pyc files they cannot be passed between different platforms. They cannot be exchanged between different Python versions either, or different distributions of the same version for the same platform. Under some circumstances, even using a different version of the compiler from that used to compile certain Python distributions can break the building process.
While the executable format differs between platforms, the Python extension API is the same. The simplest extension one can write is the following:
#include <Python.h>
PyMODINIT_FUNC initfirst(void)
{
Py_InitModule3(“first”, NULL, “Example module’s docstring.”);
}
Every extension module needs to export the init* function used by the Python interpreter during the import operation. All functions exported to Python must meet two criteria:
Be declared with PyObject*
Be declared within the PyMethodDef table.
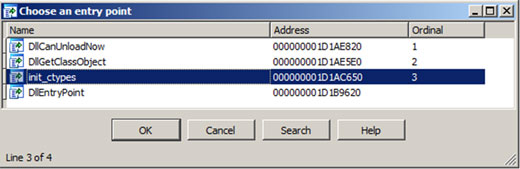
The main entry point to the DLL is obviously DllEntryPoint(), and later DllMain(). However, even a disassembly shows nothing really interesting. Below is a listing of DllMain() (64-bit) from the ctypes module:
.text:000000001D1AE850 ; BOOL __stdcall
; DllMain(HINSTANCE hinstDLL,
; DWORD fdwReason, LPVOID
; lpvReserved)
.text:000000001D1AE850 DllMain proc near ; CODE
; XREF:
; __DllMainCRTStartup+86p
.text:000000001D1AE850 ; __DllMainCRTStartup+A2p
.text:000000001D1AE850 ; DATA XREF: ...
.text:000000001D1AE850
.text:000000001D1AE850 var_18 = dword ptr -18h
.text:000000001D1AE850 hLibModule = qword ptr 8
.text:000000001D1AE850 arg_8 = dword ptr 10h
.text:000000001D1AE850 arg_10 = qword ptr 18h
.text:000000001D1AE850
.text:000000001D1AE850 mov [rsp+arg_10], r8
.text:000000001D1AE855 mov [rsp+arg_8], edx
.text:000000001D1AE859 mov [rsp+hLibModule], rcx
.text:000000001D1AE85E sub rsp, 38h
.text:000000001D1AE862 mov eax, [rsp+38h+arg_8]
.text:000000001D1AE866 mov [rsp+38h+var_18], eax
.text:000000001D1AE86A cmp [rsp+38h+var_18], 1
.text:000000001D1AE86F jz short loc_1D1AE873
.text:000000001D1AE871 jmp short loc_1D1AE87E
.text:000000001D1AE873 ; ----------------------------
.text:000000001D1AE873
.text:000000001D1AE873 loc_1D1AE873: ; CODE XREF:
; DllMain+1Fj
.text:000000001D1AE873 mov rcx, [rsp+38h+hLibModule]
; hLibModule
.text:000000001D1AE878 call cs:DisableThreadLibraryCalls
.text:000000001D1AE87E
.text:000000001D1AE87E loc_1D1AE87E: ; CODE XREF:
; DllMain+21j
.text:000000001D1AE87E mov eax, 1
.text:000000001D1AE883 add rsp, 38h
.text:000000001D1AE887 retn
.text:000000001D1AE887 DllMain endpThe DllEntryPoint function code depends heavily on the compiler used. Microsoft compilers generate code that calls __security_init_cookie (/GS switch) and then jumps to __DllMainCRTStartup. This then calls the DllMain() function. However, inspection of DLL exports shows that there are more possible entry points:
Disassembly of init_ctypes() shows a series of internal Py_() function calls to prepare the Python environment. The reason for describing all these execution paths is simple: injecting native code, hooking/inserting breakpoints or using detours in all these places allows the execution and behaviour of the Python interpreter to be manipulated. Additionally, typical native code anti-debugging and obfuscation techniques can be used in all these places to increase the complexity of the analysis process. Furthermore, since (in the case of Windows) such a module is for the operating system, another DLL can hook Windows Debugging Events in order to hijack the loading of the Python module and load different ones in its place. If such a new module conforms with the requirements of the Python interpreter for external modules, then Python will happily use it further. This ‘attack vector’ can be used in code obfuscation techniques as well as to aid in their analysis.
Python extension modules are not the only form of native code that is executed during Python interpreter execution. Python provides a set of API functions to embed its interpreter in C code. The simplest case is to call the PyRun_SimpleString() function. The argument is a C string containing Python code that the interpreter will try to execute. Another useful function is PyRun_SimpleFile(), which allows any Python source code file to be executed. (For a full list of PyRun_* functions please consult the Python documentation at http://www.python.org/doc.)
Another interesting option is to embed the complete Python interpreter into a C application. This can be accomplished with the Py_Main() function. The simple C code that allows the Python interpreter to be embedded is as follows:
Py_Initialize(); Py_Main(argc, argv); Py_Finalize();
The methods mentioned here do not cover all the possibilities of embedding and/or extending Python, however they provide a good overview of Python executable code and its format.
Now that all executable forms of Python have been described we can gain a better understanding of possible obfuscation techniques. The techniques have been divided into the groups shown in Table 2.
| Generic technique | Specific obfuscation method |
| Bytecode modification | • Header magic bytes modification • Header magic bytes truncation • Marshalled code object modification/encryption |
| Interpreter modification | • Bytecode table modification • Bytecode encryption |
| Embedding Python code | • Native code obfuscation technique |
| Pyd modules modification / hijacking | • Library modification • Library execution hijacking |
Table 2. Obfuscation techniques.
The simplest modification that stops some decompilers and all standard interpreters is the modification of the magic number at the beginning of the bytecode file. Such a change is trivial at the interpreter source code level, hence this method is very popular. Since the number of possible combinations of magic byte values is limited, and legal combinations are well known, even a simple method based on the brute force guessing of the correct value is acceptable and is simple to automate.
A simple variation of this technique is to truncate the magic number and add it during run time.
This set of techniques is based on the premise that pyc files can be distributed in obfuscated/encrypted format and decrypted just before run time. No interpreter modification is required as the whole encryption/decryption process can be performed outside of the interpreter environment. The obvious weakness of this approach is that when execution breaks during the loading of the decrypted module, one can gain access to it. The execution break may either be user-generated or the result of a bug in the module itself (for example an exception).
This method has been used increasingly frequently of late and is based on changing mapping between bytecode values and instructions. This requires changes to the Python interpreter but ensures that without the correct mappings, bytecode disassembly and proper module execution is not possible. In turn, use of the built-in dis module from the standard interpreter installation is no longer possible.
Fortunately, in order to execute such bytecode one needs the pyc file and the modified interpreter. Therefore it is possible to use the modified interpreter to get corresponding bytecode mappings and ‘decrypt’ the bytecode. The idea is quite simple and it basically comes down to the following steps:
Generate a complete set of Python opcodes by using some module source code.
Compile this module in the original interpreter and list the bytecode result.
Compile this module in the interpreter with the modified mapping and list the bytecode result.
Compare the results from steps 2 and 3 and adjust the bytecode map.
The problem with this approach is the fact that Python 2.6 has around 120 different opcodes for bytecode, so getting all possible values can be tricky. Fortunately, we don’t need to enumerate the whole bytecode table – we are only interested in the values used inside the module we are analysing. As most default Python packages (distributed in source code form) rely on standard modules (remember the slogan: ‘batteries included’) there is a good chance we can get the correct mappings by compiling files from the standard library (lib directory). In fact, step 3 can be skipped too, since the same standard modules are compiled to pyc form by default.
This technique is based on the fact that the interpreter is responsible for the Python bytecode module format it can execute. Therefore modification of the main interpreter code not only allows the use of a different bytecode table but also provides many interesting possibilities such as:
The addition of new opcodes
The changing of the pyc modules’ file format
The changing of the marshal code object.
The last option allows code objects to be encrypted during compilation and decrypted during run time in memory.
The number of possible techniques in this area is endless and is limited only by how much work is required to implement certain ‘features’.
As discussed earlier there are a few different global techniques for embedding Python code. Use of an embedded Python interpreter not only allows its behaviour to be changed, but also allows native code to be mixed with Python code. All native code obfuscation techniques (including compiling into another VM) can be applied here.
This set of techniques is heavily dependent on target system platforms. The functionality and implementation of dynamic shared objects differs significantly between the platforms on which Python can run. Nevertheless, this characteristic of Python internals can be used to further obfuscate code or completely change execution flow at run time. On the Windows platform (as mentioned already) the Windows Debugging API or detours library seem like perfect tools to accomplish such a task.
What is worth noting is the fact that this set of techniques can be performed without native code but from Python code itself. A good example is the pydbg module, which on the Win32 platform provides all the necessary debugging API functions to insert a breakpoint and therefore control DLL execution.
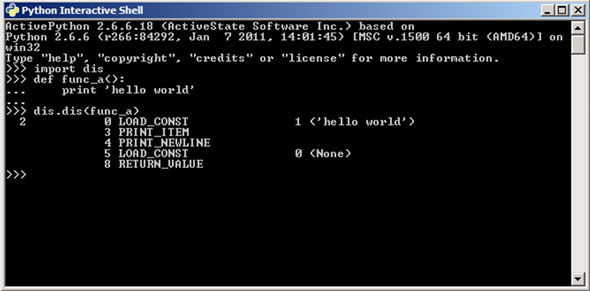
This is the only method based on source code obfuscation that I’ll describe here due to its dynamic nature. The basic idea is to store marshalled code in source code. This can easily be done thanks to Python’s dynamic nature and built-in functions like compile(), eval() and exec(). Here is an example:
>>> code_str = ‘’’print ‘Hello world!’ ‘’’
>>> bytecode = compile(code_str, ‘<string>’, ‘exec’)
>>> bytecode
<code object <module> at 00000000021ACE40, file “<string>”, line 1>
>>> exec(bytecode)
Hello world!
>>> import dis
>>> dis.dis(bytecode)
1 0 LOAD_CONST 0 (‘Hello world!’)
3 PRINT_ITEM
4 PRINT_NEWLINE
5 LOAD_CONST 1 (None)
8 RETURN_VALUEThe bytecode code object can be encrypted to further hide its meaning, and decrypted before being passed to exec()-like functions.
There are many different anti-debugging techniques mainly developed for protecting native code. However, some of these techniques can also be applied to Python code executing inside an interpreter.
It is important to remember that the Python interpreter process is just that: another process from the operating system’s point of view. For example, in the case of the Windows platform it has PEB, TEB, security tokens etc. Therefore it is possible to initiate the Python interpreter process using the Windows Debugging API. Obviously, intercepting execution of the interpreter process provides us with the ability to change its behaviour and in turn have an impact on the execution flow of the Python bytecode.
Keep in mind, however, that when conducting the process at operating system level, all the rules of anti-debugging tricks apply as well. For example, controlling a process with the Windows Debugging API leaves a lot of traces to which both the debugged process and python code have access. Therefore, to detect some debugging events we don’t even need to modify the interpreter but instead just use generic API wrappers provided by Python modules. The best example to illustrate such an approach is the use of IsDebuggerPresent() – a well-known API function used by many anti-debugging tricks. Thanks to the ctypes module, Python code can access this function and call it (Figure 4).
Obviously the rules mentioned above apply to both 32-bit and 64-bit processes and systems – but don’t forget about some important differences in the case of 64-bit architectures in the Windows Debugging API.
Since the Python interpreter is just a process running in user-land context, we can easily debug it using debuggers. Two possible approaches come to mind:
Use of source code debugging if we have access to the interpreter source code or if the interpreter comes from python.org.
Use of native code debugging in cases where the interpreter source code is not available to us.
The second situation seems more likely. Assuming the interpreter executable hasn’t been stripped of symbols there are some good ‘hooking’ points such as (WinDbg format for Python26 binary):
python26!PyInterpreterState_Head
python26!PyEval_EvalFrame
python26!PyObject_Call
python26!PyObject_CallFunction
What about cases in which symbols have been removed? The simplest approach – assuming we know the interpreter version – is to disable the original interpreter binary and extract signatures from those functions. Load the stripped interpreted executable and search for the signature within process memory. Keep in mind, however, that the compiler used for producing the executable of the custom interpreter may differ from that used for the official python.org CPython build.
As Python gains popularity, advances in anti-analysis and anti-debugging techniques will evolve faster. The mixture of bytecode, native code and external dependencies together with the simple pyc file format leaves a lot of room for more advanced techniques than those described here. It’s not a question of if we will see such new techniques but when we will see them.