2012-06-01
Abstract
With content-based anti-spam technologies decreasing in efficiency, Marius Tibeica and Adrian Toma propose a fingerprinting algorithm that maps similar text inputs to similar signatures.
Copyright © 2012 Virus Bulletin
Due to increases in spam volume, as well as language diversity, content-based anti-spam technologies have decreased in efficiency. Alternative methods of similarity/outbreak detection are much needed, and by taking advantage of technological advances in the cloud infrastructure, we can reduce the impact on clients’ resources.
To address the similarity problem, we propose a fingerprinting algorithm that maps similar text inputs to similar signatures. There are two steps: the first involves creating an element of the fingerprint from each word or group of words, chosen by certain heuristics. The size of the text on which the fingerprint is created is very important: too little information can generate false positives, and too much information can make the matching process costly. Our approach is either to zoom in (increasing the number of fingerprint elements each word generates) if the text is too short, or zoom out (gradually reducing the length by eliminating certain groups) if the text is too long. We have tested the method using a clean stream of spam to train a matching filter with the Levenshtein distance as an indicator of similarity.
Spammers constantly adapt their techniques in order to avoid detection filters. Signature-based anti-spam filters require frequent updates in order to remain effective, especially given the speed with which spam changes. Bayesian filters need constant training and can also miss spam with malicious attachments. IP address blocking is also problematic, as most spammers now rapidly change their IP addresses. Furthermore, a legitimate server that has been compromised for a short period of time cannot be blacklisted, as it also sends legitimate email messages. Spammers try to decrease the efficiency of URI blacklisting by registering a large number of domains or by using URL-shortening services. The need for an automatic similarity/outbreak detection method is clear.
The increasing popularity of portable devices and recent technological advances in the cloud infrastructure make moving processing away from the client an obvious choice – both to reduce the impact on the client’s resources and to significantly decrease update times. This shift in perspective calls for the use of a reliable fingerprint generation algorithm.
There is an existing algorithm that generates fingerprints: context-triggered piecewise hashing (also known as fuzzy hashing) [1]. Unfortunately, on text of small dimensions, the length of the signature generated by the algorithm is too small and is unusable. This represents a big portion of spam messages, and these are also the hardest to detect using other content-based filters.
Our approach to creating a fingerprint for text is to focus on the actual words contained in the message, as this gives a good separation of entities in most languages. By generating a character from each word we obtain a basic fingerprint, but this has several limitations, which we address as follows.
The creation of the basic fingerprint involves several steps:
The input string is separated into different entities by delimiters [2]. These entities can be considered words.
Entities larger than a certain threshold value can be further separated.
We apply a hash function to each entity.
A base64-encoded value of the six least significant bits of the hash is appended to the final fingerprint.
This will produce a fingerprint with a length equal to the number of entities found. If a fingerprint with a length within a certain range is needed, further processing is required.
Too little information from a fingerprint can generate false positives. To avoid this we can increase precision by gradually increasing the number of encoded values each hash appends to the final fingerprint. The number of encoded values represents the zoom level.
In this case, a 30-bit hash can offer up to five levels of zooming (for a 64-letter alphabet), and the possibility to increase the length of the fingerprints up to five times.
Too much information can make the matching process costly, especially when using a time-consuming [3] edit distance. To decrease the length of the fingerprint, we try to eliminate some of the entities in a way that gives two similar texts similar fingerprints:
To avoid losing too much information, we create new hashes from groups of entities.
For an X zoom-out level, a base64-encoded value of the six least significant bits of the hash is appended to the final fingerprint if hash % X = 0.
There is no way of finding the length of a fingerprint with a certain zoom-out level without calculating it, so zooming in will be done gradually until an acceptable length is found.
We checked several hash functions to see which offered the least number of collisions on words from emails in various languages. The best choice was RSHash.
Table 2 and Table 3 show how fingerprints with different zoom levels are generated from the text:
‘High end designer watch and handbag replica sale. Compare our price on a handful of our high end replicas!’
| Entities | Hash in hex | Basic fingerprint | 2x zoom in fingerprint | 4x zoom in fingerprint |
|---|---|---|---|---|
| high | 25c4f948 | I | EI | lE5I |
| end | 260c1435 | 1 | M1 | mMU1 |
| designer | 84f5afb | 7 | P7 | IPa7 |
| watch | 34f5dc75 | 1 | 11 | 01c1 |
| and | 2367c3d9 | Z | nZ | jnDZ |
| handbag | 1aa88b79 | 4 | o5 | aoL5 |
| replica | 33381eca | K | 4K | z4eK |
| sale | e96c2eb | r | Wr | OWCr |
| compare | 1c947587 | H | UH | cU1H |
| our | 24b80bd8 | Y | 4Y | k4LY |
| price | 3b54d80d | N | UN | 7UYN |
| on | 1777af4f | P | 3P | X3vP |
| a | 61 | h | Ah | AAAh |
| handful | 380be94e | O | LO | 4LpO |
| of | 1777af47 | H | 3H | X3vH |
| our | 24b80bd8 | Y | 4Y | k4LY |
| high | 3f155a68 | o | Vo | /Vao |
| end | 260c1435 | 1 | M1 | mMU1 |
| replicas | ad4c229 | p | Up | KUCp |
Table 2. Basic fingerprint and zooming in example.
| Entity groups | Hash in hex | 1/2x zoom out | 1/3x zoom out | 1/4x zoom out | 1/5x zoom out | 1/6x zoom out |
|---|---|---|---|---|---|---|
| high end designer | 54206878 | 4 | 4 | 4 | ||
| end designer watch | 63514ba5 | 1 | 1 | |||
| designer watch and | 60acfb49 | |||||
| watch and handbag | 73062bc7 | H | ||||
| and handbag replica | 71486e1c | c | c | |||
| handbag replica sale | 5c776d2e | u | u | u | ||
| replica sale compare | 5e63573c | 8 | 8 | 8 | ||
| sale compare our | 4fe3444a | K | ||||
| compare our price | 7ca1596c | s | s | |||
| our price on | 77849334 | 0 | 0 | 0 | 0 | 0 |
| price on a | 52cc87bd | 9 | ||||
| on a handful | 4f8398fe | + | ||||
| a handful of | 4f8398f6 | 2 | ||||
| handful of our | 743ba46d | |||||
| of our high | 7b451587 | H | ||||
| our high end | 89d97a75 | |||||
| high end replicas | 6ff630c6 | G | G | G |
Table 3. Zooming out example.
The basic and zoom-in fingerprints are generated from the same hashes, with the following results:
Basic fingerprint: I171Z5KrHYNPhOHYo1p
Fingerprint with 2x zoom in: EIM1P711nZo54KWrUH 4YUN3PAhLO3H4YVoM1Up
Fingerprint with 4x zoom in: lE5ImMU1IPa701c1jnDZaoL5z4eKOWCrcU1Hk4LY7 UYNX3vPAAAh4LpOX3vHk4LY/VaomMU1KUCp
The zoom-out fingerprints are:
1/2 x 4cu8Ks0+2G
1/3 x lHu0HG
1/4 x 4c8s0
1/5 x 4l809
1/6 x u0G
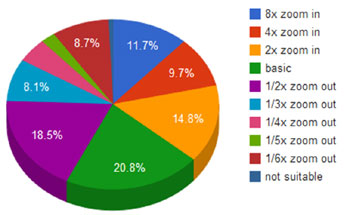
We analysed the spam flux and legitimate email messages over the course of two weeks. Setting a desired fingerprint length of 127 to 256 characters, we obtained the following results:
The cumulative results are:
Legitimate emails zoom in: 21.84%
Legitimate emails no zoom: 19.88%
Legitimate emails zoom out: 57.23%
Legitimate emails no suitable text: 0.99%
Spam emails zoom in: 36.26%
Spam emails no zoom: 20.82%
Spam emails zoom out: 42.15%
Spam emails no suitable text: 0.72%
Two fingerprints can be compared to determine whether the texts from which they were derived are similar.
Because the method of creating a fingerprint differs with each zoom level, only those with an identical zoom level can be compared. The examination looks at the zoom level and computes a Levenshtein distance, which then is scaled to produce a match score. For two fingerprints, f1 and f2, the score is:
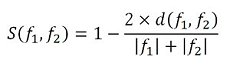
By choosing a threshold T, in the range from 0 through 1, (1 meaning that a perfect match is required), we can say that the two fingerprints match if T ≤ S (f1, f2).
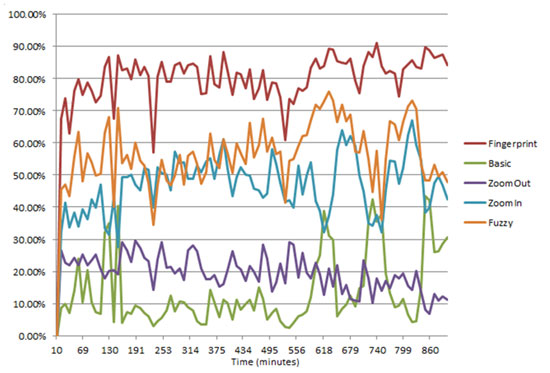
We took a continuous stream of spam (15 hours, 865,000 emails) and divided it into 10-minute intervals. For a certain interval, we trained the filter with all the emails from the previous intervals and found a detection rate with a similarity threshold of 0.75 for both fuzzy hashing (with variable block size) and the proposed fingerprinting algorithm. The results are presented in Figure 2.
We then trained the filters with all the spam emails and ran a check on a corpus of 500,000 legitimate emails and newsletters. No false positives were registered.
The fingerprinting technology was also used in between official tests in VBSpam comparative testing and the zero false-positive rate was confirmed.
The fingerprint is based on content, especially words. As long as an email message has no words (including emails that only contain images or URLs) a fingerprint cannot be generated.
[1] Levenshtein, V. I. Binary codes capable of correcting deletions, insertions and reversals. Doklady Akademii Nauk SSSR, 4, 163, 845–848, 1965.
[2] The delimiters that we chose are: {‘ ’, ‘\n’, ‘\t’, ‘\r’, ‘\0’, ‘.’, ‘,’, ‘:’, ‘;’, ‘(‘,’)’, ‘{‘,’}’, ‘[‘,’]’, ‘\\’, ‘/’, ‘^’, ‘\”’, ‘!’, ‘?’, ‘`’, ‘\’’, ‘+’, ‘*’, ‘^’, ‘$’, ‘|’, ‘?’, ‘”’}