2012-07-01
Abstract
Aleksander Czarnowski describes some of the main differences between the PE and PE+ file formats from the perspective of the binary unpacking process.
Copyright © 2012 Virus Bulletin
The x86-64 architecture is taking over from IA32 CPUs – but this should not come as a surprise, especially since major operating system players have been supporting it for years already. Of course, malware authors are aware of this revolution and thus they target executable files running natively on AMD64-compatible architectures and operating platforms. One of the most complex (and flexible) executable formats in the 64-bit world is Microsoft Windows PE32+ (since the name is a bit misleading, we will refer to it as ‘PE+’ in the rest of this article). Due to the closed-source nature of Windows, the best and most advanced debuggers and anti-debugging techniques have been developed for the Win32/64 world. Linux and BSD systems lag behind, while embedded systems for the mobile market such as Android and iOS are catching up in this area.
While not all packers/obfuscators have been upgraded to handle 64-bit executable formats, there are a lot of tools that can handle both Windows PE+ files and ELF 64-bit files. In this tutorial I will describe some of the main differences between the PE and PE+ file formats from the perspective of the binary unpacking process.
The PE+ file format is a bit like the good old 32-bit Windows PE format on steroids. If you thought you would only be able to execute a PE(+) file after successfully booting into Windows (you don’t have to log in successfully since Windows service files are also PE(+) executables internally), you would be wrong. The PE(+) file format is supported by the UEFI specification, so it is possible to execute UEFI PE files even before the target operating system or hypervisor starts. There is one important note: UEFI expects the PE+ file format even on 32-bit architecture, and furthermore it uses just a subset of PE+ features. In turn, the PE+ file format contains a special flag to mark it as UEFI executable.
Other cases for loading Win32 PE or plain PE files are limited today mostly to some DOS-based embedded solutions. But wait a minute – isn’t DOS a 16-bit real-mode operating system, whose process loader is limited to handling 64KB COM files and MZ EXEs? How can it execute Windows 32-bit protected mode binaries? The answer is simple: DOS extenders.
There are a couple of DOS extenders that offer Win32 PE support out of the box. If you thought that DOS and DOS extenders were part of the past, you would be wrong. Some DOS extenders are still actively being developed and supported: HX DOS Extender [1] is a great example. HX provides a Win32 emulation layer to DOS and enables DOS to load 32-bit PE files.
Returning to our 64-bit version of PE: if you know the PE file format well, you won’t be surprised by changes introduced in PE+. The table below summarizes most of the basic ones:
| Field | PE | PE+ |
| BaseOfData | ULONG (4 bytes) | Removed from the Optional Header |
| ImageBase | ULONG (4 bytes) | ULONGLONG (8 bytes) |
| SizeOfHeapCommit | ULONG (4 bytes) | ULONGLONG (8 bytes) |
| SizeOfHeapReserve | ULONG (4 bytes) | ULONGLONG (8 bytes) |
| SizeOfStackReserve | ULONG (4 bytes) | ULONGLONG (8 bytes) |
| StackOfSizeCommit | ULONG (4 bytes) | ULONGLONG (8 bytes) |
Table 1. Comparison between PE and PE+ formats.
The AddressOfEntryPoint field has the same size (ULONG) in both PE and PE+ files. How one can recognize a PE+ file? The magic number field in Optional Headers is different:
| Field | PE | PE+ |
| Magic Number | 0x10b | 0x20b |
PE+ executable images are restricted to a maximum size of two gigabytes, so relative addressing with a 32-bit displacement can be used to address static image data. This data includes the import address table, string constants, static global data, and so on.
The rest of the PE+ file looks like a PE file – and what’s more important is that all compression/obfuscation tools that handle PE+ files work in exactly the same way as in the case of 32-bit executable images. Therefore, the unpacking process is also similar. The following sections describe some of the other important differences that the 64-bit architecture brings in.
All general purpose registers are extended to 64-bit width in long mode, providing us with RAX, RBX, RCX, RDX, RSI, RDI, RBP, RSP and RIP, which serves like its 32-bit brother EIP as an instruction pointer. New general purpose registers have also been introduced (it seems as if the AMD and Intel engineers finally decided that they envied some of the good old Motorola 68K features): from R8 to R15. New XMM registers are also available: from XMM8 to XMM15. All XMM registers are of 128-bit width. 64-bit MMX0–MMX7 registers are available as well.
x64 Windows systems no longer use the STDCALL calling convention by default. Instead, the FASTCALL convention is used, which means that the first four parameters are passed in RCX, RDX, R8 and R9 registers. Further parameters are passed using the stack. There are no attempts to spread a single argument across many registers. Additionally, the caller is responsible for allocating parameter space to the callee, and must always allocate sufficient space for the four register parameters, even if the callee doesn’t have that many parameters [2].
Following [3], here is a typical function prolog:
mov [RSP + 8], RCX push R15 push R14 push R13 sub RSP, fixed-allocation-size lea R13, 128[RSP]
And here is a typical function epilog:
add RSP, fixed-allocation-size pop R13 pop R14 pop R15 ret
It is worth mentioning that while in long mode some of the 16/32-bit instructions are unavailable and can generate an undefined opcode exception (#UD).
Furthermore, opcodes from 40h to 4fh (inc register/dec register) have a different mapping in long mode. The REX prefix uses those while in long mode.
String operation instructions like LODSB, STOSB etc. have been extended to handle 64-bit addressing. In turn, a few new string instructions have been introduced: LODSQ, CMPSQ, MOVSQ, SCASQ and STOSQ. As a consequence, REPx prefixes handle 64-bit registers as well as LOOP, LOOPZ and LOOPNZ. All those string instructions can be found in decompression/decryption loops.
Furthermore, both SYSENTER and SYSEXIT instructions are available from legacy mode. In long mode, the SYSCALL/SYSRET pair is used.
If, during unpacking, you see some of these unavailable instructions in your disassembly, you can be assured that either the unpacking process has gone wrong, or it has not yet finished.
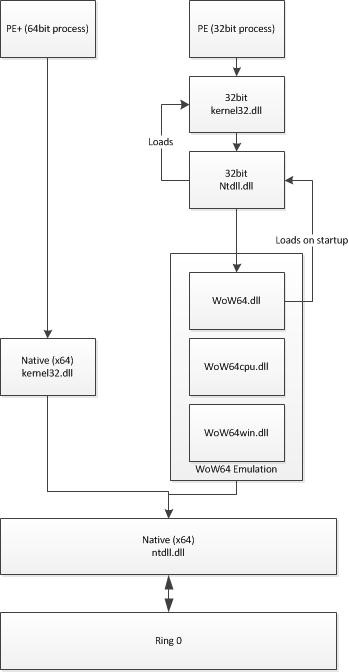
WOW64 is an emulation layer that enables AMD64 and Itanium-based Windows systems to execute Win32 applications to maintain backwards compatibility. Figure 1 describes the high-level WOW64 architecture. It is worth mentioning that WoW64.dll loads a 32-bit version of ntdll.dll, which loads other 32-bit DLLs that are needed to support Win32 application execution. Most of these DLLs are exact binary copies from the 32-bit system, however some have been modified in order to be able to share resources with 64-bit system components.
Note that in the case of Itanium-based systems there are two more libraries involved in running 32-bit software:
IA32Exec.bin – contains an x86 software emulator.
Wowia32x.dll – provides an interface between WOW64 and IA32Exec.bin.
Since this is a tutorial, I’ve decided not to use a specific malware sample. Instead, I have created a sample PE+ file written in assembly language. This file can be compiled with flat assembler (fasm), which is available at [4]. Do not try to compile this example with different assemblers such as MASM or NASM as you will not succeed without editing the source code. The presented examples use specific fasm syntax. I’ve chosen fasm since it provides a lot of control over output executable files within the source code level and no external linker is needed in our case. For example, you can manually control the layout of PE+ sections, their order and attributes:
; Example of 64-bit PE program
format PE64 GUI
entry start ;Entry point definition
;DATA SECTION
section ‘.data’ data readable writeable
_caption db ‘Win64 assembly program’,0
_message db ‘Hello World!’,0
;CODE SECTION
section ‘.text’ code readable executable
start:
sub rsp,8*5 ; reserve stack for API use and make stack dqword aligned
mov r9d,0
mov r8,_caption
mov rdx,_message
xor rcx,rcx
call [MessageBoxA]
mov ecx,eax
call [ExitProcess]
; IMPORT SECTION
section ‘.idata’ import data readable writeable
dd 0,0,0,RVA krnl_name,RVA krnl_tbl
dd 0,0,0,RVA user_name,RVA user_tbl
dd 0,0,0,0,0
krnl_tbl:
ExitProcess dq RVA _ExitProcess
dq 0
user_tbl:
MessageBoxA dq RVA _MessageBoxA
dq 0
krnl_name db ‘KERNEL32.DLL’,0
user_name db ‘USER32.DLL’,0
_ExitProcess dw 0
db ‘ExitProcess’,0
_MessageBoxA dw 0
db ‘MessageBoxA’,0
To compile the file just enter: fasm.exe testwin64.asm. Assuming that the compilation succeeded you can now load the binary file into IDA Pro using the standard Open File option. This will be our template file that we will use for all further operations. The file sections and attributes are shown in Figure 2.
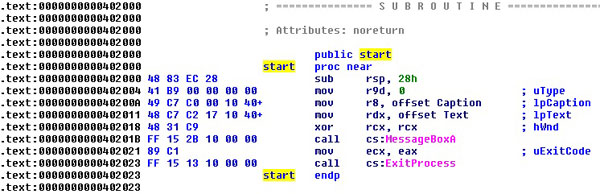
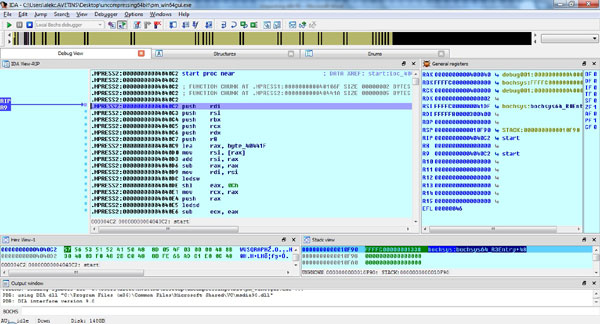
Next, disassemble the entry point using the Ctrl+E shortcut to jump directly to the start label, as shown in Figure 3. You can see that the data closely resembles our fasm source – now you know why I have chosen fasm for this job: the source code is quite similar to the resulting EXE file.
Take a note of the instruction bytecodes forming the entry point and entry point address: 0x0402000. This address will later be our original entry point address (OEP).
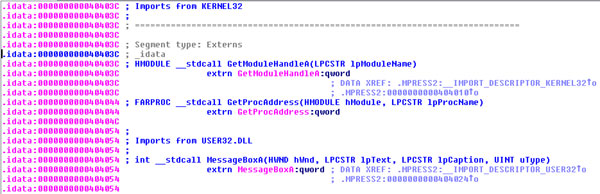
Next, let’s inspect the import section and list imports using the ‘Imports’ subview from IDA Pro (Figure 4). Since we have used only two functions, MessageBoxA and ExitProcess, only those two are listed.
The next step is to generate the target file. In order to do that we will compress our test file so that we will be able to make a comparison with the original during the unpacking process.
I’ve chosen the mpress [5] file packer since it is freely available and handles both PE and PE+ files. In order to create a new, compressed executable file, follow the commands shown in Figure 5. We use –i options since the resulting compressed file will be larger than the original one. By default, mpress refuses the compression and creation of a new executable if the resulting output file is bigger than the input. Observant readers might notice that our test file can also be used as a base for measuring the efficiency of compression algorithms. Additionally, the test file is a perfect target for reversing the compression stub since the original EXE file has such a simple construction.
Obviously, any native 64-bit debugger supported by IDA Pro requires Windows on the x64 platform. Fortunately, the Bochs plug-in allows you to debug both PE and PE+ binaries inside Bochs, even on 32-bit platforms. The speed impact due to code emulation can be ignored in most cases during malware analysis and unpacking files. The next advantage of the Bochs plug-in, when analysing hostile code, is that the code is ‘executed’ in a virtual, controlled environment. The recently disclosed SYSRET privilege escalation vulnerability (CVE-2012-0217) demonstrates the risk associated with running hostile code inside hypervisors. The disadvantage of emulation is obvious – there are no 100% perfect emulators of bare metal hardware and the real operating system. There is a set of methods that can be used to detect if code is being executed under Bochs emulation. For some of the most basic methods see [7].
When using Bochs in PE operation mode, keep in mind that in the current version there are some important limitations:
PE+ support is limited.
Windows environment emulation is limited and this can lead to its easy detection by the process.
Thread and process manipulations are not supported – this could render the Bochs plug-in useless against more advanced compression/obfuscation methods combined with anti-debugging tricks.
Only a handful of API calls are implemented.
LoadLibrary() works only on DLLs defined in the startup.idc file before running the debugger.
Fortunately, some important Windows features such as TLS callbacks, SEH and crucial Windows structures are available. Furthermore, bochsys.dll exports the BxUndefinedApiCall() function, which catches unimplemented API calls. Setting a breakpoint on it allows such a situation to be trapped or for the end of the unpacking process to be detected. Bochsys.dll exports another useful function: BxIDACall(). Setting a breakpoint on this function allows all API calls that are handled internally by IDA Pro to be monitored.
The uunp plug-in is a demonstration plug-in bundled with IDA Pro. It is available from the ‘Edit->Plugins-> Universal unpacker manual reconstruct’ menu option. As a side note: Windows 32-bit plug-ins use the *.plw file extension, while 64-bit ones use *.p64. They all reside in the plug-ins directory of the IDA Pro installation folder. Looking at the limitations of the Bochs plug-in and some additional information required by the uunp plug-in (Figure 6), you might be wondering why we are not using another plug-in distributed with IDA Pro: Universal PE Unpacker. We will discuss the Universal PE Unpacker internals in the second part of this tutorial.
The uunp plug-in does the following:
Locates the Import Address Table (IAT).
Creates an XTRN segment to represent imports.
Generates a new entry point (OEP) in the IDA database while deleting the old one used by the packer.
Forces reanalysis of new code sections.
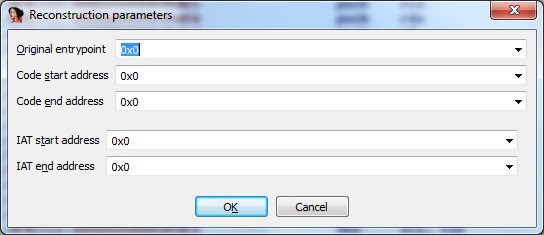
Figure 6. uunp plug-in main window – you need to enter the correct information manually in order to get the desired results.
However, in order to get a reasonable output from the uunp plug-in we need to feed it manually with the proper addresses of the original file. The only way we can find out the requested information is to execute or emulate decompression code. The most important pieces of information we need to gather are: the original entry point (OEP) address and the Import Address Table (IAT) start and end address. The value for the ‘Code end address’ field could theoretically be guessed, however this is not recommended when analysing malware.
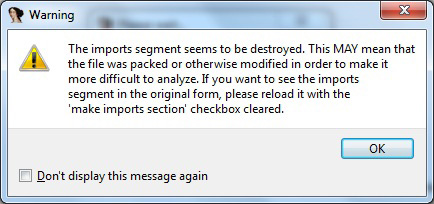
Let’s start with the default PE+ file loader from IDA Pro – in order to do that, just open the compressed test file. The default PE+ file loader (Figure 7) will warn us about the Import Table section (Figure 8).
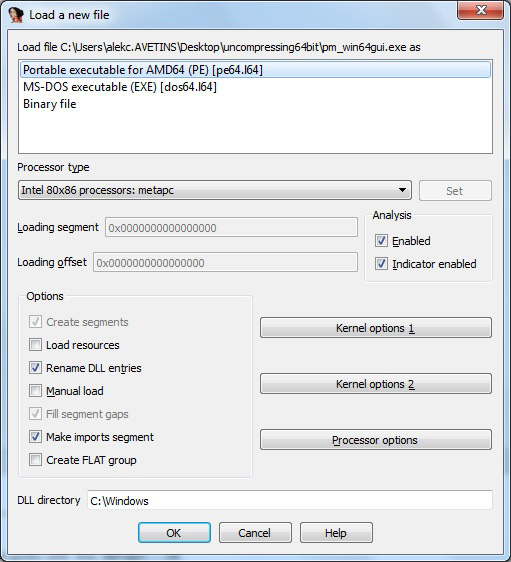
Figure 7. Loading the compressed file – note that the ‘Make imports segment’ option is enabled by default.
Next we should examine our PE+ file layout in memory using the option ‘View->Open subviews->Segments’ (shift+F7 is the default shortcut). Figure 9 shows that there are three segments, named .MPRESS1, .MPRESS2, .MPRESS2 and .idata (this is not a mistake: the .MPRESS2 name is used twice, but the two segments have different start addresses). Note that segments in IDA Pro are not directly equal to executable file sections. In our case, segments have been created automatically by IDA Pro. A different list of segments will be created if we load our PE+ file with the ‘Make imports segment’ option disabled.

Figure 9. IDA Pro automatically generates segments of the compressed file with the ‘make imports segment’ options enabled.
Since the name ‘.idata’ suggests that IDA Pro has somehow created an Import Address Table section (marked as XTRN), we can inspect it, but first let’s check which imports IDA detected. Use the ‘View->Open subviews->Imports’ option to list all imports (Figure 10). Only three Windows functions are imported: GetModuleHandleA, GetProcAddress and MessageBoxA. Inspection of the ‘.idata’ segment confirms our findings (Figure 11). At least one obvious function import is missing from this picture: LoadLibrary and VirtualProtect come to mind.
Since it was detected in the imports, we can assume that GetProcAddress is being used by the decompression loop. Therefore, we can either manually analyse and trace code under the debugger in order to find its invocation or we can set up a breakpoint at GetProcAddress. Since this is a tutorial, setting up a breakpoint at GetProcAddress is not a bad idea. It will not only allow us to verify our hypothesis that functions found in the import table are used to recreate the original IAT, but also to inspect how IDA Pro cooperates with Bochs at a low level. This knowledge may be helpful in the future in case of more advanced assignments.
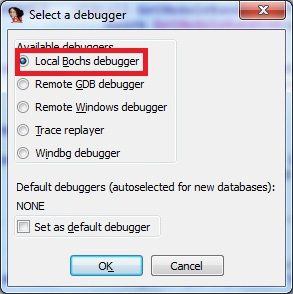
Before running the Bochs debugger plug-in we need to configure it. From the ‘Debugger’ menu choose ‘Select debugger option’. From this window select ‘Local Bochs debugger’ (see Figure 12).
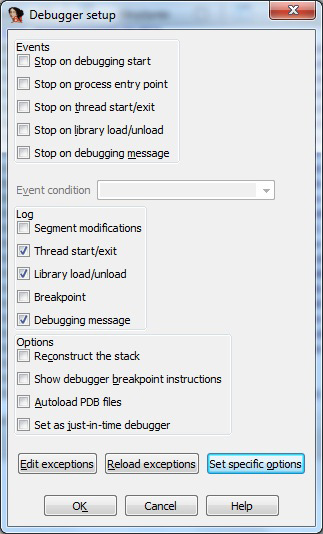
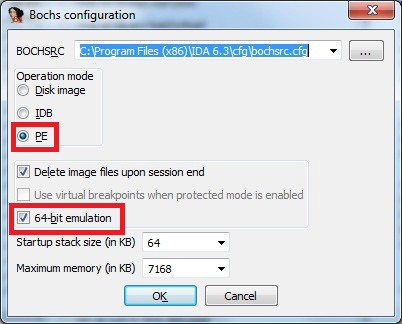
Next, again from the ‘Debugger’ menu, select ‘Debugger options…’ – a new configuration window will open (Figure 13). From this window click the ‘Set specific options’ button to display another window, as shown in Figure 14. Be sure to enable 64-bit support and PE file support in this window.
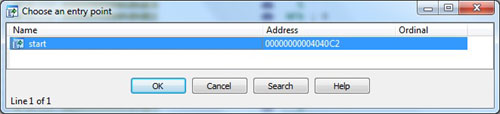
Now we are ready to start unpacking our target file. First go to the PE+ entry point – this can be done by pressing Ctrl+E and selecting one of the possible addresses (Figure 15). In our case, IDA Pro detected only one entry point and labelled it ‘start’. This is obviously not our Original Entry Point. Let’s add a breakpoint at the entry point. Press F2 at the entry point (0x04040C2 address in our case) and start a debugger. This can be done either by pressing the green ‘play’ icon on the toolbar or by pressing the F9 key. Take a second to look at the navigation bar – the current entry point is located near the end of the file: many compression/obfuscation tools just add their code after the original file end. This could be a hint that the OEP may be located below the current entry point, however at this point this is only a hypothesis.
After pressing the F9 key (Run), the debugger should stop at the first instruction. Now we can finally add a breakpoint at the GetProcAddress function. In order to do so, open the ‘Breakpoints’ list from the ‘Debugger->Breakpoints->Breakpoint list’ menu. Now press the ‘insert’ key to add a new breakpoint. At the ‘location’ field enter ‘kernel32_GetProcAddress’ (remember that the kernel32 name is misleading since we are dealing with the 64-bit version despite the ‘32’ in the name) and click ‘OK’. Now, run the debugger again (F9) and wait until the GetProcAddress function breakpoint has been hit. Our function should look like this:
KERNEL32.dll:0000000078D26455 kernel32_GetProcAddress: KERNEL32.dll:0000000078D26455 push cs:off_78D2645C KERNEL32.dll:0000000078D2645B retn
Use ‘step into’ (F7) options to execute the retn instruction. The next function should be within the bochsys module:
bochsys:FFFFC00000001467 bochsys64_BxGetProcAddress: ; DATA XREF: KERNEL32.dll:off_78D2645Co bochsys:FFFFC00000001467 mov rax, 0FFFFC00000001467h bochsys:FFFFC00000001471 call near ptr bochsys64_BxIDACall bochsys:FFFFC00000001476 retn
We can ‘step over’ this code until we reach the retn instruction. This is a stub code used by the Bochs plug-in to communicate with IDA, as mentioned earlier. After executing the retn instruction we return to our module inside the .MPRESS1 section:
.MPRESS1:00000000004010D4 test eax, eax .MPRESS1:00000000004010D6 jz short loc_401103 .MPRESS1:00000000004010D8 push rax .MPRESS1:00000000004010D9 push rsp .MPRESS1:00000000004010DA pop r9
This is obviously the code that checks the success of GetProcAddress (test eax,eax). Now let’s open the Imports window and jump to GetProcAddress import (Figure 17):
Now you see there is a cross reference j_GetProcAddress – jump to it (Figure 18).
There is another cross reference at .MPRESS1:0x0401152. Once again, jump to that cross reference to find the following code:
MPRESS1:000000000040114F loc_40114F: ; CODE XREF: .MPRESS1:0000000000401141j .MPRESS1:000000000040114F mov rcx, rbx ; hModule .MPRESS1:0000000000401152 call j_GetProcAddress .MPRESS1:0000000000401157 stosq .MPRESS1:0000000000401159 .MPRESS1:0000000000401159 loc_401159: ; CODE XREF: .MPRESS1:0000000000401161j .MPRESS1:0000000000401159 xor al, al .MPRESS1:000000000040115B mov [rsi-1], al .MPRESS1:000000000040115E lodsb .MPRESS1:000000000040115F or al, al .MPRESS1:0000000000401161 jnz short loc_401159 .MPRESS1:0000000000401163 jmp short loc_401132
The stosq instruction should store the address returned by the GetProcAddress() function at the location pointed to by the RDI register. The RDI register value during the first iteration of this loop will point to the original IAT. Consequently, at this address the RDI register during the last iteration will point to the end of the IAT. Note both values, since these are required by the uunp plug-in.
Stepping over this loop we can see how the IAT is being reconstructed and finally, when we reach the following code, we have found the jump to the original entry point:
MPRESS1:0000000000401165 exit_to_oep: ; CODE XREF: .MPRESS1:0000000000401118j .MPRESS1:0000000000401165 lea rdi, loc_40106F .MPRESS1:000000000040116C mov al, 0E9h .MPRESS1:000000000040116E stosb .MPRESS1:000000000040116F mov eax, 10Ch .MPRESS1:0000000000401174 stosd .MPRESS1:0000000000401175 add rsp, 28h .MPRESS1:0000000000401179 pop r8 .MPRESS1:000000000040117B pop rdx .MPRESS1:000000000040117C pop rcx .MPRESS1:000000000040117D pop rbx .MPRESS1:000000000040117E pop rsi .MPRESS1:000000000040117F pop rdi .MPRESS1:0000000000401180 jmp OEP_at_0x402000
A few important observations should be made at this point:
The packer does not use the popa instruction before jumping to the original entry point (some 32-bit compressors use it). Therefore, any universal unpacking methods based on detecting the popa instruction before jumping to OEP will fail. Popa/popad is not valid in long mode, as mentioned earlier (however POPFQ is).
We can use the long list of pop instructions ending with the jmp as a signature to look for the original entry point address. Note that our OEP is actually at a higher address than the decompression exit code. This means that any plug-in trying to automatically detect the OEP based on a jump below the decompression loop in memory will also fail.
At this point we can feed the uunp plug-in with the data we have gathered during our debugging session.
Manual unpacking obviously does not scale well in production environments. Therefore, plug-ins like uunp can be treated only as a simple demonstration of IDA Pro’s scripting abilities and plug-ins/modules architecture. If you are willing to automate the unpacking process with IDA Pro, or the case you are working on requires some special treatment/tricks, you have a couple of options that might help you:
Write a custom loader module – all examples here were based on IDA Pro default PE+ loader. However, you can either load a file manually, bypassing the loader (this option is quite handy when some uncommon PE+ format tricks are used), or implement your own loader. This could be handy if you are able to automatically decompress original code and data plus reconstruct the import table. Obviously this requires either some knowledge about how a certain packer works, or use of a more generic approach based on execution/emulation of code.
Write a custom processor module – this option is especially handy when, besides the compression/encryption algorithm, some kind of virtual machine/bytecode scheme has been used in order to further obfuscate the original executable code.
It turns out that unpacking 64-bit PE files doesn’t really differ much from unpacking 32-bit EXEs or DLLs. The only difference is the limited number of tools that can handle the PE+ format correctly.
Furthermore, both 32- and 64-bit architectures allow complex compression, encryption and obfuscation techniques, and since PE(+) structures add some complexity to the equation, we are yet to see new techniques. Of course, the complexity of PE+ will increase as natural Windows platform evolution introduces new bugs and vulnerabilities into the process loader. I’m afraid that those vulnerabilities are likely to be exploited sooner rather than later.
In the second part of this tutorial (which will appear in the August issue of VB) I will dig a bit more deeply into Windows x64 internals, use some of IDA Pro’s scripting functionality and use WinDbg to unpack our example file. In the meantime, if you would like to see another example of unpacking an mpress binary with IDA Pro take a look at the blog post at [9].
[1] HX DOS Extender. http://www.japheth.de/HX.html.
[2] MSDN: Overview of x64 Calling Conventions. http://msdn.microsoft.com/en-us/library/ms235286(v=vs.80).aspx.
[3] MSDN: Prolog and Epilog. http://msdn.microsoft.com/en-us/library/tawsa7cb(v=vs.80).aspx.
[4] flat assembler. http://flatassembler.net/.
[5] mpress. http://www.matcode.com/mpress.htm.
[6] UPX. http://upx.sourceforge.net/.
[7] Ferrie, P. Attacks on Virtual Machine Emulators. https://www.symantec.com/avcenter/reference/Virtual_Machine_Threats.pdf.
[9] Unpacking mpress’ed PE+ DLLs with the Bochs plugin. http://www.hexblog.com/?p=403.