2014-06-02
Abstract
As indicated by the considerable payouts we see being made for valid security vulnerabilities, finding valuable 0-days is not an easy task. Fuzzing – the most common approach to bug hunting – is technologically and scientifically well developed and well documented, yet simply running some fuzzers isn't enough to achieve the desired outcome. Alisa Esage attempts to pin down the secret ingredient for successful bug hunting.
Copyright © 2014 Virus Bulletin
While the focus of fashionable security research is constantly shifting towards new targets, such as hardware and cloud security, 0-day vulnerability research has never lost its value. In fact, its value has continually risen, as demonstrated by the increase in the number of bug bounty and exploitation contest programs in existence, and their ever-increasing payouts. This year, a total of $850,000 was awarded to Pwn2Own contestants for successful exploitation of 0-day vulnerabilities in popular software [1]. Another bug monetization entity, the Zero Day Initiative, has for many years paid researchers for the responsible disclosure of valid security vulnerabilities (no exploit required), paying around a few thousand USD each time (this has been confirmed by the author).
As these considerable payouts suggest, finding valuable 0-days (that is, exploitable security vulnerabilities in popular software) is not an easy task. Even though fuzzing – which is the most common approach to bug hunting – is technologically and scientifically well developed and well documented, simply running some fuzzers (which is indeed easy to do) is not going to achieve the desired outcome. There seems to be a secret ingredient to finding valuable bugs – one that is missing from the books and publications on the subject. The main objective of the research behind this article was to find that secret ingredient, and to generalize it so that it could be applied to completely arbitrary targets (i.e. everything).
The main measure of research success was assumed to be the ratio of exploitable (as reported by automated tools) vulnerabilities to total number of bugs found in popular software. The secondary measure of success was the total number of bugs found with limited resources, as an indication of a potent fuzzing vector with popular software. By means of these two criteria and some of my own research, I have drawn some conclusions as to what makes a good fuzzing technique.
Regardless of the secret ingredient for fuzzing success, the first thing one needs is a good fuzzing framework.
There are a considerable number of fuzzing tools readily available on the Internet, both free and commercial. However, none of them satisfied the objectives of this research due to the following limitations:
They were too specialized. For example, they would only fuzz browsers, or only files. They were not suitable for fuzzing everything by design.
They enforced unnecessary constraints. For example, glue mutation with data feeding and automation with crash analysis. This kills flexibility and scalability, and thus, is not suitable for fuzzing everything.
There was a steep learning curve. All fuzzing frameworks had their own template format and specific configuration. We have to ask whether it is worth the investment of learning a system that is largely constrained anyway.
An ideal fuzzer – one that is suitable for finding security vulnerabilities in arbitrary software – should possess the following properties:
Omnivorous: It should be target invariant – i.e. independent of software type, data type, platform and architecture.
Omnipresent: It should be hosting-platform invariant – i.e. it should be equally capable of working on VM/hardware/localnet/clouds.
Autonomous: It should be able to be left to run on its own. It should rotate mutations/seeds automatically.
‘LEGO’-style modular architecture: One should be able to mix and match components, enabling rapid support for new targets and hot patching for tweaking.
Unlimited, native scaling: It should be possible to have any number of fuzzers running at the same time. It should take very little time to set up new targets.
Immediately actionable output: It should perform auto-analysis of crashes, sort unique cases and send an email with the stats.
Available now: It should be available right now – we don’t have the time for development, and the system must be usable from day one.
To satisfy these requirements, the system’s specific functions must be well segregated and ultimately generalized (abstract). We assume the following system design decisions:
A network client-server architecture
Built upon isolated, generic tools
Native automation (bash, cmd/PowerShell, cscript/wscript, AppleScript etc.)
Native instrumentation (DebugAPI, CrashWrangler, cdb postmortem scripts etc.)
Generic mutators (home-made bit-flipping tools, grep/sed/urandom, Radamsa).
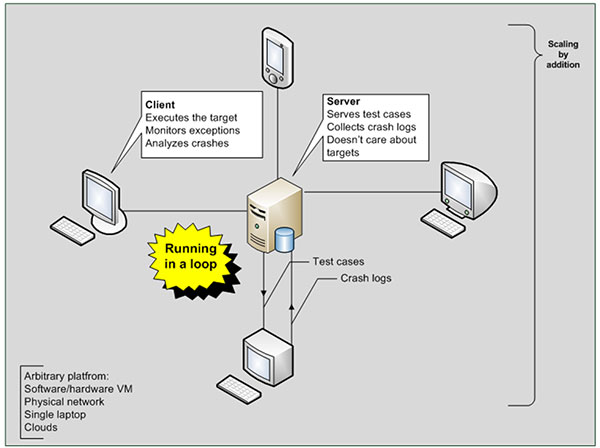
As shown in Figure 1, the system’s functions are segregated as follows:
Server
Generates and serves test cases
Accepts and sorts crash analysis logs
Provides scripts for additional pre-analysis, sorting, particular trigger location
Client:
Executes the target software in a loop
Monitors exceptions
Analyses crash dumps
Whole system:
Runs in a loop
Scales natively by addition of new clients
Runs on any platform thanks to native automation tools.
As was noted in the introduction to this article, a decent fuzzing framework is necessary in order to start producing crashes, but it is not enough to find those elusive exploitable security vulnerabilities. So, where’s the magic?
It has been seven years since the publication of the canonical book Fuzzing: Brute Force Vulnerability Discovery [2], and 10 years since the publication of the first edition of The Shellcoder’s Handbook [3]. Since then, dozens of research papers have been published, hundreds of fuzzing tools have been developed and shared with the community, and thousands of vulnerabilities have been discovered. In 2014, fuzzing is a mature industry, driven not by art or technology, but by the market and competition.
A common mistake made by beginners in this industry is to assume that success in fuzzing is defined by the fuzzer’s speed and size. This is not exactly true, as proven by the success of a few independent researchers against Google’s own ClusterFuzz [4]. To put it simply, one needs millions of test cases if the majority of those test cases are bad (i.e. rejected by the target’s data validation routines, or unable to reach or trigger any vulnerable code). Thinking along this logic, one might conclude that the main thing that matters in fuzzing is to target bug-rich branches of code.
The problem here is that there is no simple algorithmic solution for discovering such bug-rich branches of code on a major scale or for complex data formats. Code coverage allows for the measuring of the volume of code paths that have already been reached, but it doesn’t help in discovering new code segments. Evolutionary input generation only allows new code paths to be discovered on a tiny assembly-level scale, not on the scale of a complex data format. Think of an RTF document with an embedded Word document with embedded ActiveX – how long would it take to evolve such a complex sample from a generic seed? Probably forever. However, my experience shows that it’s exactly this kind of complex sample that targets the most ‘fresh’ code in applications.
Thus, discovering potent fuzzing vectors remains largely the responsibility of human intelligence.
Let’s think: where can it possibly be, this bug-rich code base?
Clearly, unknown or unpopular software is rich with an unaudited code base, because no one cares about it. And nor do we. As per popular software which everyone cares about, the density of ‘previously unknown’ bugs in various segments of code is primarily defined by the competition’s assumptions and research patterns.
Part of the code base in a known, popular piece of software may still be bug-rich – for example, the code may not be obvious to reach or easy to trigger.
One example is the TIFF 0-day discovered in the wild in 2013 (CVE-2013-3906). The vulnerability lies within the Microsoft Office ogl.dll graphics processing module, which is specific to Office 2007. In every other Office version, embedded images are processed by the Windows native module gdiplus.dll. This means that this vulnerability could only be found by fuzzing Office 2007 specifically with documents containing embedded malformed images – not a common vector with fuzzing graphics or documents.
Another example is CVE-2014-0315, the Insecure Library Loading vulnerability in Windows’ handling of .cmd and .bat files. Vulnerabilities of this type are quite easy to find and are generally considered all to have been fixed long ago, but they are still being found in 2014.
The third example is CVE-2013-1324, the Microsoft Office .wpd file vulnerability. This is a stack-based buffer overflow – the trivial type of bug which was considered to have been eliminated long ago, but has still been found in the latest versions of Microsoft Office.
To summarize, some places to look for non-obvious code bases are:
Ancient, rarely used code bases
Hidden functionalities
Software-specific source code for a system’s native functionality.
A code base may long remain bug-rich if reaching it requires considerable effort.
One example is the use-after-free vulnerability in Microsoft’s RDP ActiveX (CVE-2013-1296). ActiveX modules are an easy target and should, in theory, be well audited already. The possible reason why this ActiveX remained vulnerable in 2013 is that public tools for fuzzing ActiveX don’t support vulnerabilities of the use-after-free type.
Another example is the Microsoft DKOM/RPC service, which exposes ports 135 and 445 on a typical Windows system. This is a huge, complex and completely undocumented code base that has yet to be targeted by researchers.
So, some more signs of under-audited code bases worthy of our attention are:
Those for which public fuzzing tools have limitations (easily augmented)
Those with undocumented data formats (easily addressed by generic tools).
A code base may be under-audited because it was previously assumed to be too constrained to be valuable for exploitation, e.g. due to extra security controls or user interaction.
One example is, again, the system-standard ActiveX in Windows. Modern versions of Internet Explorer require user interaction to enable an ActiveX, so this is not considered to be an interesting vector for research. The misconception here is that IE is not the only software capable of loading and controlling an ActiveX (think Microsoft Word).
In summary, what I have concluded to be the minimum requirements for successful fuzzing are the following:
Research! The primary target should be code bases, not data formats or data input interfaces or fuzzing automation technology. Look for ancient code, hidden/non-obvious functionality, etc.
Bet on complex data formats. For complex data, code paths exist which are not reachable automatically – which means their code bases have probably never been audited and there will be no competition.
Craft complex fuzzing seeds manually. The rule of ‘minimal size sample’, as stated in [2], is obsolete in 2014.
Remove one to two data format layers before injecting malformed data. Deep parsers are less well audited (because researchers are lazy?) and they tend to contain more bugs (because programmers are lazy?).
Estimate the potency of a new vector by dumb fuzzing prior to investing in smart fuzzing. Use the assumption that bugs tend to crowd in the direction of a ‘less well audited’ code base.
Tweak a lot to get a ‘feeling’ for the particular target.
Keep the fuzzing setting dirty. Fuzzing is dirty by design. Incorporating it nicely into a well-designed system kills the flexibility that is necessary for tweaking and rapid prototyping.
Do more research.
[1] Pwn2Own 2014: A Recap. http://www.pwn2own.com/2014/03/pwn2own-2014-recap/.
[2] Sutton, M.; Greene, A.; Amini, P. Fuzzing: Brute Force Vulnerability Discovery. http://www.fuzzing.org/.
[3] Koziol, J.; Litchfield, D.; Aitel, D.; Anley, C.; Eren, S.; Mehta, N.; Hassell, R. The Shellcoder’s Handbook: Discovering and Exploiting Security Holes. First Edition. 2004.
[4] Google Chromium Security Hall of Fame. http://www.chromium.org/Home/chromium-security/hall-of-fame/.