2015-03-02
Abstract
Dénes Óvári describes a PoC file that demonstrates a new way to store data in PDF files.
Copyright © 2015 Virus Bulletin
Some years ago, developers of exploit kits began to use malformed PDF files as attack vectors for malicious drive-by downloads, usually by exploiting vulnerabilities present in viewer applications. Detections were duly added to AV products and as a result, the generated PDF files became increasingly obfuscated as malware attempted to circumvent the scanners.
Typically, advantage was taken of the wide range of filters that are provided by the PDF specification for streams in a document. Besides the various text encodings and common data compressors such as Deflate and LZW, even image compressors such as CCITTFaxDecode [1] and JBIG2Decode [2] were seen storing payloads in the wild – all due to the fact that a binary stream can usually be interpreted as raw image data.
Consequently, scanners were upgraded to handle the compression of streams in PDF files. However, mainly for performance reasons, certain assumptions had to be made about the filters. For example, streams compressed using lossy compressors like JPXDecode and DCTDecode (which is a JPEG-compatible filter) are skipped by scanners and even by popular PDF forensics tools – indicating that their use for the storage of malicious payloads has been deemed impossible by their developers.
In a presentation about PDF heuristics [3], the presence of DCTDecode streams in a document was said to be indicative of a clean file. This was with good reason, of course – the PDF specification states that the uncompressed data would only be an approximation of the original data [4], implying exclusive use of the filter for photograph-like images.
But is that really the case? JPEG compression has a couple of options, and likewise the PDF specification contains a handful of ways to determine how the decompressed data should be interpreted.
Briefly: after optionally downsampling some of the components, the baseline JPEG splits the image data into 8x8 pixel blocks (MCUs). The original unsigned values are scaled to signed values by subtracting 128 (see MCU number 1 with sample image data in Figure 1). Afterwards, the data is transformed to the frequency domain by means of a two-dimensional discrete cosine transform (see Figure 1).

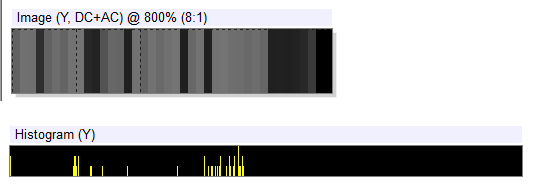
Figure 1. (1) MCU with sample image data; (2) data is transformed by means of a two-dimensional discrete cosine transform.
(Click here to view a larger version of Figure 1.)
The results from DCT (called coefficients) are divided with a quality factor (qf) dependent quantization matrix (see Figure 2). Rounding of the results leads to the dropping of certain high-frequency components of the image (see Figure 2) – and that is the stage at which most of the data loss occurs. Finally, all of the processed data is losslessly compressed using a form of Huffman coding.
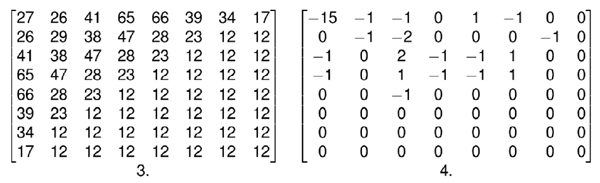
Figure 2. The coefficients are divided with a quality factor dependent quantization matrix (3); rounding of the results leads to the dropping of certain high-frequency components of the image (4).
Decompression is performed backwards: in a nutshell, the data is multiplied with the quantization table, an inverse DCT is performed, and the values are shifted back to the 0–255 range.
At high qf settings, with floating-point precision DCT calculation, it would be possible to store and retrieve raw RGB data losslessly, using software like GIMP, for example. However, JPEG implementations differ – quantization tables and certain stages of decompression are entirely up to the developer, therefore the output might be different when the stream is decompressed with another library.
In the most popular PDF reader application, Acrobat Reader, we can see that Adobe’s JPEG implementation could alter some samples in the LSB +/- 1 range [5]. This is completely reasonable for image reproduction and conforms to the JPEG specification, while making the misuse of DCTDecode to store arbitrary data also impossible at first sight.
However, only the colour mode of JPEG has been inspected so far, where the image is actually stored in the YCbCr colour space, using certain properties of the human visual system to increase efficiency. Practically, this means converting RGB values into luminance (Y) and two chrominance (Cb, Cr) components with a set of equations [6] before encoding.
If these calculations are computed with finite precision, rounding errors could occur, causing information loss – certain RGB values are impossible to represent in the output. Since at high qf settings, the quantization tables contain only 1s, it could be assumed that actually all of the information loss was due to this conversion.
This assumption can be verified because JPEG has a separate greyscale mode. Omitting any colour space conversion, using only the luminance layer, every 24 bits of incoming data represent only a single pixel of the image.
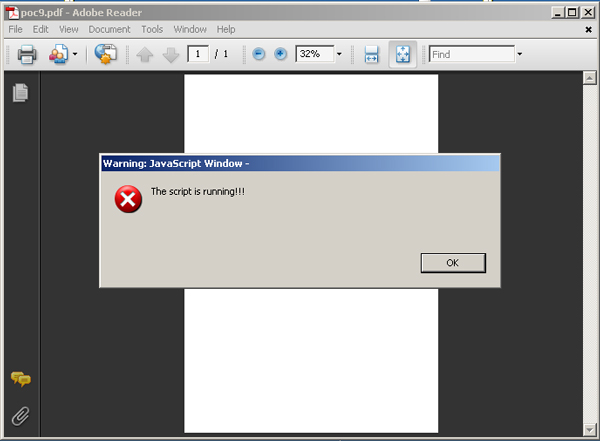
A PoC file was made, where a short script was encoded as a greyscale JPEG image with the highest quality setting. The script was padded with 0x00 bytes until the next MCU boundary, and this was repeated seven more times. Then it was placed in an Image object filtered with DCTDecode, which was referenced by a JavaScript action entry.
When opening the document, the alert dialog just pops up under the old Reader 9 (Figure 4), proving that the code of the short script was decompressed losslessly.
Under Reader XI, certain bits changed in the decompressed data, rendering the original file unusable. However, simply changing a couple of characters in each MCU of the stream until the decompressed data looked as it was expected to was enough for the file to work again.
Following the introduction of a sandbox for JavaScript code in Acrobat Reader, the use of PDF as an attack vector decreased dramatically. However, the PoC file described here demonstrates a new way to store data in PDF files. Although this is not a security breach in itself (an exploit still needs to be used inside the stream for malicious activity), the fact that the usage of DCTDecode for this purpose has seemingly been ruled out by the industry means that even known threats could be hidden in this way from anti-virus scanners and/or researchers.
Click here to view a larger version of Figure 5.)
In order to provide users with maximum protection, the DCTDecode stream must no longer be overlooked: in PDF reader implementations, the referencing of uncompressed image data as parameters from objects expecting binary data should be prohibited. We should also perhaps re-examine the handling of other file formats in which data in JPEG format is assumed always to be lossily compressed, while a greyscale mode is still available.
[1] Baccas, P. PDF malware adopts another obfuscation trick in attempt to avoid detection. http://nakedsecurity.sophos.com/2012/04/05/ccittfax-pdf-malware/.
[2] Sejtko, J. Another nasty trick in malicious PDF. http://blog.avast.com/2011/04/22/another-nasty-trick-in-malicious-pdf/.
[3] Baccas, P. Malicious PDFs: A summary of my VB2010 presentation. http://nakedsecurity.sophos.com/2010/10/08/malicious-pdfs-points-vb2010-presentation/.
[5] Supporting the DCT Filters in PostScript Level 2. Technical Note #5116, Adobe Systems Incorporated. Section 23.
[6] Hamilton, E. JPEG File Interchange Format, version 1.02. http://www.w3.org/Graphics/JPEG/jfif3.pdf (p.3).
![]()